Cracking the Odd Case of Randomness in Java
A technique for exploiting insecure randomness in Java with practical applications
A technique for exploiting insecure randomness in Java with practical applications
This blog post details a technique for cracking Apache Commons Lang 3 RandomStringUtils.randomAlphanumeric(count) and more generally, Java’s java.util.Random.nextInt(bound) for odd values of bound. As far as we are aware, this is a novel approach and improves upon the existing techniques for attacking Java’s random number generation in this specific case. We have implemented the attack and released it publicly here.
During a recent white-box assessment, we came across the use of RandomStringUtils.randomAlphanumeric being used in a security sensitive context. We knew it used Java’s weak java.util.Random class but were interested in seeing how practically exploitable it actually was, so we decided to dig into it and see how it worked under the hood.
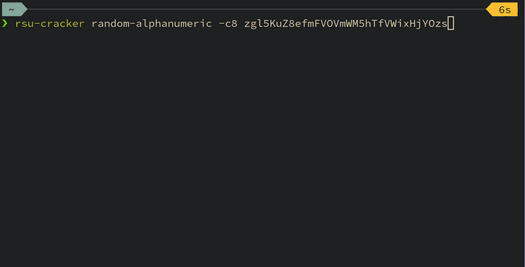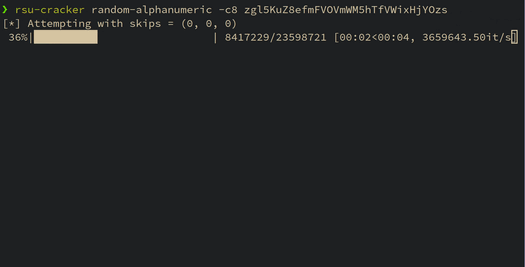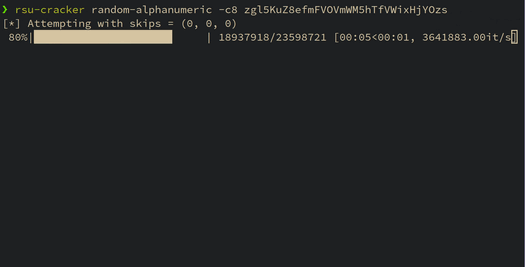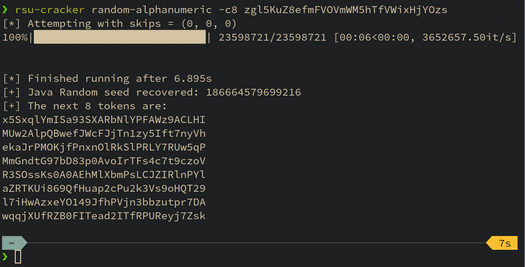
After a few days of staring at equations and debugging off-by-ones, we ended up with a tool that could recover the Java Random instance seed and predict future outputs of RandomStringUtils.randomAlphanumeric in under a minute on average. We realised this approach led to a more general attack against java.util.Random.nextInt(bound) for odd values of bound so extended the tool to support this too.
In this blog post, we’ll look at some prior work in this area, give some background about RandomStringUtils and Java’s random number generation, then finally go through our approach of attacking it.
Before diving in, we scoured the internet for existing research or tools to make sure we weren’t reinventing the wheel. The underlying algorithm of java.util.Random is a linear congruential generator, so we began our search there, looking specifically at generic attacks against truncated LCGs which is close to what RandomStringUtils.randomAlphanumeric and java.util.Random.nextInt use. Truncated LCGs have been studied extensively; there are papers, tools and some CTF challenges about breaking them, but none of these seemed to be directly applicable to our situation at hand.
Getting closer to the concrete problem itself, we found a few tools targeting java.util.Random.nextInt specifically. fransla/randcrack is able to crack java.util.Random.nextInt(bound) but only treats the case of even values of bound. It does this by using the fact that when the bound is even, a few bits of the state are directly leaked in the outputs. This script uses a similar idea for the specific case of bound = 4 but attacks the truncated LCG with lattice reduction techniques. A shortcoming of these tools we found is that their underlying ideas don’t apply when the bound is odd, which as we’ll see, is the case for RandomStringUtils.randomAlphanumeric. 14/02/23 Update: After publishing this blog post, we were made aware of mjtb49/LattiCG which implements a generic way of recovering a Java Random seed that satisfies certain output conditions in the form of inequalities. This tool uses lattice reduction techniques and a branch and bound algorithm which manages to also handle the case when the bound is odd. Similarly to the tool presented in this post, this tool slows down as the bound gets very small, but both are still quite practical for most applications. The approach we use in our tool is a lot more elementary, but manages to perform just as well or better than existing tools in most cases.
After a bit more searching, we eventually stumbled across alex91ar/randomstringutils which implements a practical exploit against RandomStringUtils.randomAlphanumeric – exactly what we were looking for! The approach used in this tool takes advantage of the first character of the output string to reduce the search space. While this is a great tool and could serve our purpose, even running on 20 cores it can still take up to an hour to recover the state.
We decided there were ways to do this more efficiently, so we started our research into new ideas.
This section will give a brief overview of RandomStringUtils.randomAlphanumeric and java.util.Random. It can be safely skipped if you are already familiar with how these work.
Apache Commons Lang 3 is a popular Java library that provides all sorts of helper utilities. One such utility is the RandomStringUtils class which is commonly used to generate random alphanumeric strings with the RandomStringUtils.randomAlphanumeric method. The API is simple – a call to RandomStringUtils.randomAlphanumeric(count) returns a string containing exactly count alphanumeric characters.
Although the second line of the documentation page warns that the randomness used in this class is not cryptographically secure, the use of these methods in security sensitive contexts is unfortunately not too rare.
Let’s go through the source and see how the randomness is used.
As in the comments of the constructor method, the RandomStringUtils class is intended to be used for its static methods only. As such, it defines a static member RANDOM which is an instantiation of java.util.Random with no arguments.
import java.util.Random;
[...]
public class RandomStringUtils {
/**
* <p>Random object used by random method. This has to be not local
* to the random method so as to not return the same value in the
* same millisecond.</p>
*/
private static final Random RANDOM = new Random();
/**
* <p>{@code RandomStringUtils} instances should NOT be constructed in
* standard programming. Instead, the class should be used as
* {@code RandomStringUtils.random(5);}.</p>
*
* <p>This constructor is public to permit tools that require a JavaBean instance
* to operate.</p>
*/
public RandomStringUtils() {
}Looking at the definition of the randomAlphanumeric(int count) method, we see it calls random(count, true, true) which itself will end up calling random(count, 0, 0, true, true) which will finally call random(count, 0, 0, true, true, null, RANDOM). These method definitions are listed below:
/**
* <p>Creates a random string whose length is the number of characters
* specified.</p>
*
* <p>Characters will be chosen from the set of Latin alphabetic
* characters (a-z, A-Z) and the digits 0-9.</p>
*
* @param count the length of random string to create
* @return the random string
*/
public static String randomAlphanumeric(final int count) {
return random(count, true, true);
}
/**
* <p>Creates a random string whose length is the number of characters
* specified.</p>
*
* <p>Characters will be chosen from the set of alpha-numeric
* characters as indicated by the arguments.</p>
*
* @param count the length of random string to create
* @param letters if {@code true}, generated string may include
* alphabetic characters
* @param numbers if {@code true}, generated string may include
* numeric characters
* @return the random string
*/
public static String random(final int count, final boolean letters, final boolean numbers) {
return random(count, 0, 0, letters, numbers);
}
/**
* <p>Creates a random string whose length is the number of characters
* specified.</p>
*
* <p>Characters will be chosen from the set of alpha-numeric
* characters as indicated by the arguments.</p>
*
* @param count the length of random string to create
* @param start the position in set of chars to start at
* @param end the position in set of chars to end before
* @param letters if {@code true}, generated string may include
* alphabetic characters
* @param numbers if {@code true}, generated string may include
* numeric characters
* @return the random string
*/
public static String random(final int count, final int start, final int end, final boolean letters, final boolean numbers) {
return random(count, start, end, letters, numbers, null, RANDOM);
}This final random method that is called is where the interesting stuff happens. We’ve added some comments to annotate the code keeping in mind that this method is called with the arguments random(count, 0, 0, true, true, null, RANDOM).
/**
* <p>Creates a random string based on a variety of options, using
* supplied source of randomness.</p>
*
* <p>If start and end are both {@code 0}, start and end are set
* to {@code ' '} and {@code 'z'}, the ASCII printable
* characters, will be used, unless letters and numbers are both
* {@code false}, in which case, start and end are set to
* {@code 0} and {@link Character#MAX_CODE_POINT}.
*
* <p>If set is not {@code null}, characters between start and
* end are chosen.</p>
*
* <p>This method accepts a user-supplied {@link Random}
* instance to use as a source of randomness. By seeding a single
* {@link Random} instance with a fixed seed and using it for each call,
* the same random sequence of strings can be generated repeatedly
* and predictably.</p>
*
* @param count the length of random string to create
* @param start the position in set of chars to start at (inclusive)
* @param end the position in set of chars to end before (exclusive)
* @param letters if {@code true}, generated string may include
* alphabetic characters
* @param numbers if {@code true}, generated string may include
* numeric characters
* @param chars the set of chars to choose randoms from, must not be empty.
* If {@code null}, then it will use the set of all chars.
* @param random a source of randomness.
* @return the random string
* @throws ArrayIndexOutOfBoundsException if there are not
* {@code (end - start) + 1} characters in the set array.
* @throws IllegalArgumentException if {@code count} < 0 or the provided chars array is empty.
* @since 2.0
*/
public static String random(int count, int start, int end, final boolean letters, final boolean numbers,
final char[] chars, final Random random) {
if (count == 0) {
return StringUtils.EMPTY;
} else if (count < 0) {
throw new IllegalArgumentException("Requested random string length " + count + " is less than 0.");
}
if (chars != null && chars.length == 0) {
throw new IllegalArgumentException("The chars array must not be empty");
}
// start and end are both 0, so this branch is taken
if (start == 0 && end == 0) {
if (chars != null) {
end = chars.length;
} else if (!letters && !numbers) {
end = Character.MAX_CODE_POINT;
} else { // chars is null, but letters and numbers are both true, so this branch is taken
end = 'z' + 1;
start = ' ';
}
} else if (end <= start) {
throw new IllegalArgumentException("Parameter end (" + end + ") must be greater than start (" + start + ")");
}
final int zero_digit_ascii = 48;
final int first_letter_ascii = 65;
if (chars == null && (numbers && end <= zero_digit_ascii
|| letters && end <= first_letter_ascii)) {
throw new IllegalArgumentException("Parameter end (" + end + ") must be greater then (" + zero_digit_ascii + ") for generating digits " +
"or greater then (" + first_letter_ascii + ") for generating letters.");
}
final StringBuilder builder = new StringBuilder(count);
final int gap = end - start; // gap equals 91
while (count-- != 0) {
final int codePoint;
if (chars == null) { // chars is null, so this branch is taken
// since start is 32 and gap is 91, this set codePoint to a random number between 32 and 122 (inclusive)
codePoint = random.nextInt(gap) + start;
// none of these are ever hit when codePoint is between 32 and 122
switch (Character.getType(codePoint)) {
case Character.UNASSIGNED:
case Character.PRIVATE_USE:
case Character.SURROGATE:
count++;
continue;
}
} else {
codePoint = chars[random.nextInt(gap) + start];
}
// Character.charCount(codePoint) will always be 1 when codePoint is
// between 32 and 122, so this branch is never taken
final int numberOfChars = Character.charCount(codePoint);
if (count == 0 && numberOfChars > 1) {
count++;
continue;
}
// since the characters in the range between 32 and 122 contains some non-alphanumeric characters,
// this branch is taken only some of the time
if (letters && Character.isLetter(codePoint)
|| numbers && Character.isDigit(codePoint)
|| !letters && !numbers) {
builder.appendCodePoint(codePoint);
if (numberOfChars == 2) {
count--;
}
} else {
count++;
}
}
return builder.toString();
}If we focus on just the important parts, we can roughly summarise the RandomStringUtils.randomAlphanumeric method with the Python code:
def random_alphanumeric(count):
start = ord(' ')
end = ord('z') + 1
gap = end - start
out = ''
while len(out) < count:
code_point = next_int(gap) + start
if chr(code_point).isalnum():
out += chr(code_point)
return outThe interesting thing to us here is that, from outputs of this method, we can more or less recover outputs of RANDOM.nextInt(91). From here, we can transform the problem into cracking java.util.Random in this particular case, so let’s turn our attention there!
There are some great resources on how java.util.Random works and how to break it in some simple cases, so we’ll just give a simple overview here.
The java.util.Random class is Java’s default pseudorandom number generator (PRNG). By pseudorandom, we mean that its outputs are not truly random; they are determined by the seed value we initialise the PRNG instance with. There are many ways to implement PRNGs, and in the case of java.util.Random, a linear congruential generator (LCG) is used.
An LCG has three important parameters; a multiplier $A$, an addend $C$ and a modulus $M$. For java.util.Random, these parameters are set to $A = \mathrm{0x5DEECE66D}, C = \mathrm{0xB}$ and $M = 2^{48}$. Given a seed $x_0$, which is simply a number between $0$ and $M$, the state is advanced by computing
Some of $x_1$ is then outputted and $x_1$ becomes the new state. If another random number is needed, the state gets advanced again by computing
\[x_2 = (Ax_1 + C) \mod M\]and some of $x_2$ is outputted. $x_2$ then becomes the new state, and so on… At any point in time, the state is simply a 48-bit number, and if we know that value, we can predict any future output.
In code, we can see this happening here:
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}This method returns an output containing the specified number of bits. The line where nextseed is assigned is equivalent to
and the outputted value is simply this new state truncated to the number of bits required.
The problem of breaking this construct is then to recover any of the $x_i$ values given some outputs. Of course, if the output was the full value of $x_i$ then it is trivially broken. However, in java.util.Random, no more than 32 bits of $x_i$ is ever outputted (i.e. next is never called with an argument larger than 32).
Our target of interest is the nextInt(int bound) method. After understanding how it works, our ultimate goal will be to devise a way of learning about the $x_i$ values from outputs of it.
public int nextInt(int bound) {
if (bound <= 0)
throw new IllegalArgumentException(BAD_BOUND);
int r = next(31);
int m = bound - 1;
if ((bound & m) == 0) // i.e., bound is a power of 2
r = (int)((bound * (long)r) >> 31);
else { // reject over-represented candidates
for (int u = r;
u - (r = u % bound) + m < 0;
u = next(31))
;
}
return r;
}This method returns an integer between 0 and bound-1 (inclusive) chosen uniformly at random. It does so by first calling the next method to generate a random 31-bit value r. If the specified bound is a power of 2, then it immediately returns (bound * r) >> 31. We aren’t really interested in this case, so let’s focus on the weird looking for loop. The purpose of this loop is to ensure uniformity. For relatively small values of bound, it is very unlikely that this loop condition will be satisfied, so for the purposes of cracking RandomStringUtils.randomAlphanumeric, we could more or less ignore it. But for completeness, let’s try to understand what it’s doing. All of the values involved are 32-bit signed integers, so u - (u % bound) + m < 0 will only hold true if the left-hand side overflows. Instead, we could write this as u - (u % bound) + m > 2^31 which holds over the integers. From this, we have u - (u % bound) > 2^31 - m and so we can see why this is very unlikely to hold the smaller bound and m are; because the smaller m is, the closer to 2^31 u will have to be. As a concrete example, if bound = 5, then the only values of u which will cause the condition to be true are 2147483645, 2147483646 and 2147483647 and this will only occur $3/2^{31} \approx 0.00000014\%$ of the time. As noted in the docs, the worst case occurs when the bound is $2^{30} + 1$, in which case the condition is satisfied with a probability of $1/2$.
With the background out of the way, let’s take a look at how to break RandomStringUtils.randomAlphanumeric. Our problem is to essentially break java.util.Random given (almost) consecutive outputs of nextInt(91).
Recall that RandomStringUtils.randomAlphanumeric generates alphanumeric characters by computing nextInt(91) + 32 and taking this code point to be an output character if it corresponds to an alphanumeric character. There are 62 alphanumeric characters, and so $62/91 \approx 68.1\%$ of the time the generated code point is used. This means that $29/91 \approx 32.9\%$ of the time, we essentially “skip” an output of nextInt(91). For the time being, we’ll ignore the fact that this happens and just assume that we can obtain consecutive outputs of nextInt(91). We’ll come back to this later.
Suppose we have a string obtained from a call to RandomStringUtils.randomAlphanumeric(10). Let $c_1, \ldots, c_{10}$ denote the ASCII values of the characters of the string. Let $y_i = c_i - 32$, so that $y_i$ is essentially the $i$th output of nextInt(91). Assuming no skips occurred, we can write the equations:
Here, $\gg$ denotes the logical right shift operation and $x_i$ is the $i$th state of the LCG, with $x_0$ being the seed. Recall that the $x_i$ are related by the LCG relation:
\[x_i = (Ax_{i-1} + C) \mod M\]where $A, C$ and $M$ are the multiplier, addend and modulus of Java’s LCG.
Focusing on the first output, we have
\[y_1 = (x_1 \gg 17) \mod{91}\]which can be written as an equation over the integers:
\[y_1 = (x_1 \gg 17) + 91k_1\]where $k_1$ is some integer satisfying $\lvert k_1 \rvert < \lceil 2^{31}/91 \rceil$. This bound comes from the fact that $(x_1 \gg 17)$ is a 31-bit number. This equation gives us the first idea for an attack that does better than bruteforcing all $2^{48}$ possible seed values. The idea is that we can bruteforce over the possible values of $k_1$, then computing $y_1 - 91k_1$ gives us a candidate for $x_1 \gg 17$. For each such candidate, we can then bruteforce over the $2^{17}$ possible values of $x_1 \mod 2^{17}$ to obtain candidates for $x_1$. We can then check which state value agrees with the rest of the outputs to determine the correct candidate. The total amount of bruteforce required here is approximately $\lceil 2^{31}/ 91 \rceil \cdot 2^{17} \approx 2^{41.5}$. This is the trick used by alex91ar/randomstringutils which brings cracking RandomStringUtils.randomAlphanumeric into feasibility for regular people.
But from an information theoretic perspective, if we only use the first output to narrow the search space for the state, then there’s no way we can do better than reducing the search space by $6.5$ bits (the approximate number of bits we obtain from seeing one output of nextInt(91)). So the natural idea is to look at the next outputs and to see if we can extract any information out of them. We do this by writing equations and staring at them:
This equation is interesting because the only unknown is $x_1$. For simplicity of notation, let’s write $x_1 = x_{1,U_{31}} + x_{1,L_{17}}$ where $2^{17} \leq x_{1,U_{31}} < 2^{48}$ represents the upper 31 bits of $x_1$ and $0 \leq x_{1,L_{17}} < 2^{17}$ represents the lower 17 bits of $x_1$. The equation can then be written as
\[\begin{aligned} y_2 &= (((A(x_{1,U_{31}} + x_{1,L_{17}}) + C) \mod M) \gg 17) \mod{91} \\ \implies y_2 &= (((Ax_{1,U_{31}} + Ax_{1,L_{17}} + C) \mod M) \gg 17) \mod{91} \\ \implies y_2 &= (((((Ax_{1,U_{31}} + C) \mod M) \\ &\qquad + (Ax_{1,L_{17}} \mod M)) \mod M) \gg 17) \mod{91} \end{aligned}\]In the last step, we separated out the $Ax_{1,U_{31}} + C$ and $Ax_{1,L_{17}}$ values. Because both of these values modulo $M$ can be at most $M-1$, after adding them and reducing the result modulo $M$, the reduction would have either done nothing or subtracted $M$. So we could instead write the equation as
\[\begin{aligned} y_2 &= ((((Ax_{1,U_{31}} + C) \mod M) \\ &\qquad + (Ax_{1,L_{17}} \mod M) - b_2 M) \gg 17) \mod{91} \end{aligned}\]where $b_2 \in \{ 0, 1 \}$.
Next, we aim to separate $Ax_{1,U_{31}} + C$ and $Ax_{1,L_{17}}$ across the right shift operation. Although logical right shift is not distributive over addition, we do have the identity
\[(a + b) \gg n = (a \gg n) + (b \gg n) + c, \qquad c \in \{0, 1\}\]Also keeping in mind that $M = 2^{48}$, we have $b_2 M \gg 17 = b_2 2^{31}$, so we can write
\[\begin{aligned} y_2 &= ((((Ax_{1,U_{31}} + C) \mod M) \gg 17) \\ &\qquad + ((Ax_{1,L_{17}} \mod M) \gg 17) - b_2 2^{31} + c_2) \mod{91} \end{aligned}\]where $c_2 \in \{0, 1\}$.
Staring at this equation gives us a second idea for an attack that does a lot better than the first. The idea is to consider the expressions involving $x_{1,U_{31}}$ and $x_{1,L_{17}}$ separately to perform a meet-in-the-middle attack. More specifically, the outline is as follows.
Using the first output $y_1$ with the equation
\[y_1 = (x_1 \gg 17) \mod{91} \implies y_1 - 91k_1 = x_{1,U_{31}}\]enumerate over the $\lceil 2^{31} / 91 \rceil$ possible values of $k_1$ to generate $\lceil 2^{31} / 91 \rceil$ candidate values for $x_{1,U_{31}}$.
Using the candidates of $x_{1,U_{31}}$ obtained from the first step, compute the “left hand side” value
\[(y_2 - (((Ax_{1,U_{31}} + C) \mod M) \gg 17)) \mod{91}\]and associate the candidate of $x_{1,U_{31}}$ with this value, which will be between $0$ and $90$.
Note that each value between $0$ and $90$ will have approximately $2^{31} / 91^2$ candidates of $x_{1,U_{31}}$ associated with it on average.
Enumerate over the $2^{17}$ candidates for $x_{1,L_{17}}$ and compute the “right hand side” value
\[(((Ax_{1,L_{17}} \mod M) \gg 17) - b_2 2^{31} + c_2) \mod{91}\]with all combinations of $b_2 \in \{0, 1\}$ and $c_2 \in \{0, 1\}$. In total, there will be $2^{17} \times 2 \times 2 = 2^{19}$ values computed. As with the left hand side values, associate the candidate of $x_{1,L_{17}}$ with the computed value between $0$ and $90$.
For each of the right hand side values computed in the third step, look up the matching left hand side values. This gives us a list of approximately $2^{31} / 91^2$ candidates for $x_{1,U_{31}}$ to look through for each of the $2^{17}$ candidates of $x_{1,L_{17}}$. Given candidates for $x_{1,U_{31}}$ and $x_{1,L_{17}}$ together, we have a candidate for $x_1$. We can then use this state value and check whether or not it agrees with the rest of the outputs to determine the correct candidate.
The meet-in-the-middle approach introduces a space-time complexity tradeoff. We need to store around $2^{31} / 91$ values which are each 32 bits. In practice and depending on the actual data structures and types used, this requires a few hundred MB of memory. However, the improvement in time complexity is worthwhile; on average we would expect the required amount of bruteforce to be $2^{19} \times 2^{31} / 91^2 \approx 2^{37}$.
While this is an improvement, we can do even better by extending this idea to use more outputs. Consider the equation for the third output
\[\begin{aligned} y_3 &= (x_3 \gg 17) \mod{91} \\ \implies y_3 &= (((Ax_2 + C) \mod M) \gg 17) \mod{91} \\ \implies y_3 &= (((A(Ax_1 + C) + C) \mod M) \gg 17) \mod{91} \\ \implies y_3 &= ((A^2x_1 + AC + C) \mod M) \gg 17) \mod{91} \\ \end{aligned}\]As we did with the second output, this can be rewritten as
\[\begin{aligned} y_3 &= ((((A^2x_{1,U_{31}} + AC + C) \mod M) \gg 17) \\ &\qquad + ((A^2x_{1,L_{17}} \mod M) \gg 17) - b_3 2^{31} + c_3) \mod{91} \end{aligned}\]where $b_3 \in \{0, 1\}$ and $c_3 \in \{0, 1\}$.
To use both outputs at once, we proceed with step 1 as usual, but on the second step we compute the left hand side values for both the second and third outputs and associate the candidate for $x_{1,U_{31}}$ with the pair of left hand side values. Specifically, for each candidate of $x_{1,U_{31}}$, we compute
\[\begin{aligned} L_1 &= (y_2 - (((Ax_{1,U_{31}} + C) \mod M) \gg 17)) \mod{91}\\ L_2 &= (y_3 - (((A^2x_{1,U_{31}} + AC + C) \mod M) \gg 17)) \mod{91} \end{aligned}\]We then associate that candidate for $x_{1,U_{31}}$ with the pair $(L_1, L_2)$. Note that since $L_1, L_2 \in \{0, \ldots, 90\}$, there are $91^2$ possible values for the pair $(L_1, L_2)$. So we expect each pair to have approximately $2^{31}/91^3$ candidates of $x_{1,U_{31}}$ associated with it.
We do so similarly with the third step for the right hand side values, computing
\[\begin{aligned} R_1 &= (((Ax_{1,L_{17}} \mod M) \gg 17) - b_2 2^{31} + c_2) \mod{91} \\ R_2 &= (((A^2x_{1,L_{17}} \mod M) \gg 17) - b_3 2^{31} + c_3) \mod{91} \end{aligned}\]for the $2^{17}$ possible values of $x_{1,L_{17}}$ and every combination of $b_2, b_3, c_2, c_3 \in \{0, 1\}$. In total, we compute $2^{17} \times 2^4 = 2^{21}$ values. Finally, we look up the left hand side pairs which match with $(R_1, R_2)$ and check the correctness of the resulting candidate for $x_1$.
The total amount of bruteforce required is now around $2^{21} \times 2^{31} / 91^3 \approx 2^{32.5}$.
We can see that using an extra output reduces the complexity of the last step by approximately $4.5$ bits. The first step remains at around $2^{31} / 91$ however also increases by a small factor per extra output used. Furthermore, using more outputs adds a little bit of extra complexity when taking skips into consideration. We don’t have any other way of handling skips, so we deal with them by simply bruteforcing reasonable skip amounts and running the same algorithm many times. Since a skip occurs $29/91 \approx 32.9\%$ of the time, we start bruteforcing the number of skips starting from no skips. If we use three outputs to compute the left and right hand side values, then no skips will occur approximately 32% of the time. Less than two skips in total will cover just over 80% of cases, and we would expect less than 2% of cases to have six or more skips. We found that using three outputs worked quite well on average.
In our approach for attacking RandomStringUtils.randomAlphanumeric we essentially attacked random.nextInt(91). There was nothing too specific to RandomStringUtils.randomAlphanumeric other than the consideration of skips which itself was somewhat of an afterthought. So we can use the same idea for attacking random.nextInt(bound) when bound is odd by simply replacing $91$ with the bound in our above approach. There are a few notes we can make about attacking random.nextInt(bound) more generally however:
nextInt start to occur with significant probability. Fortunately, this only happens when the bound values are very large, in which case using only one output is sufficient. We can simply bruteforce the skip amount up to a reasonable amount.random.nextInt(bound), although can be adjusted to account for non-consecutive outputs.A lot of projects use RandomStringUtils, and a lot of these projects use them in places where they shouldn’t. The video below demonstrates the usage of our tool in a proof-of-concept exploit against an application that uses RandomStringUtils to generate passwords for password resets. The attacker requests a password reset for their own account and then for the target’s account. By using their newly generated password, they can break the randomness and predict what the target’s password will be.
This post looked at the inner workings of RandomStringUtils and Java’s default cryptographically weak PRNG and explored a new way of attacking these constructs. We developed and released a tool which can crack RandomStringUtils.randomAlphanumeric to predict future outputs in less than a minute on average. The tool is also capable of cracking Java’s java.util.Random.nextInt(bound) for odd values of bound on which there has not been much prior work.
There are some limitations and rooms for improvement however – the approach is not effective for cracking random.nextInt(bound) when the bound is very small (i.e. less than 7) and is sometimes unable to recover the seed. The tool could also be extended to support rewinding the state to generate previous outputs, which may be convenient in some applications.
Overall, the tool has proven to be practically useful as it has helped us develop proof of concept exploits quicker and more reliably. It also has potential to be helpful in black box tests and for bug bounty hunters as it could be used to quickly determine whether a suspicious looking parameter is vulnerable or not without having access to the source code.
Finally, if you are a developer, keep in mind that insecure randomness and cryptographic failures in applications may lead to easily exploitable vulnerabilities with high impact. Pay close attention to security and cryptography and ensure the randomness used in security sensitive contexts within your application is cryptographically secure.
That’s about it, thanks for reading!
Cracking the Odd Case of Randomness in Java
December 2025 - ORM Leaking More Than You Joined For
November 2025 - Gotchas in Email Parsing - Lessons From Jakarta Mail
March 2025 - New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
October 2024 - A Monocle on Chronicles
August 2024 - DUCTF 2024 ESPecially Secure Boot Writeup
July 2024 - plORMbing your Prisma ORM with Time-based Attacks
elttam is a globally recognised, independent information security company, renowned for our advanced technical security assessments.
Read more about our services at elttam.com
Connect with us on LinkedIn
Follow us at @elttam
 ORM Leaking More Than You Joined For
ORM Leaking More Than You Joined For
By Alex Brown December 18, 2025
A follow-up article in our ORM Leaks series covering newly susceptible ORMs, techniques for bypassing ORM Leak protections, and demonstrating how ORM Leaks can exist in any web application that uses one.
 Gotchas in Email Parsing - Lessons From Jakarta Mail
Gotchas in Email Parsing - Lessons From Jakarta Mail
By Jia Hao Poh November 17, 2025
This writeup goes through the various primitives in Jakarta Mail that could lead to high impact bugs if developers are unaware of the library's quirks. Primitives discussed here here can be applied to other mail parsing libraries.
 New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
New Method to Leverage Unsafe Reflection and Deserialisation to RCE on Rails
By Alex Brown March 04, 2025
This blog article documents a new unsafe reflection gadget in the sqlite3 gem, that can also be used in a deserialisation gadget chain to achieve RCE and is installed by default in new Rails applications.